

The rapid success of Alexa and similar voice control services is actually the convergence of several trends and technologies, such as the proliferation of ubiquitous connectivity, search, and streaming audio, as well as breakthroughs in automated speech recognition (ASR) and natural language processing. New digital signal processing methods such as multi-microphone beamforming and talker tracking have made voice control feasible in noisy environments and at increasing distances — from headset to hands-free to “far field” or across the room.
Great Audio Will Drive Market Success
Key to improving voice interaction with voice-enabled devices is a focus on higher performance audio and acoustic technology. An ounce of prevention in the acoustic design is worth a pound of cure in the ASR backend. By reducing the influence of external noise in the environment surrounding the smart speaker, cloud-based voice services (e.g., Amazon Alexa) will be better able to hear and process commands, thus improving performance and user experience.
Turnkey solutions exist to perform “front-end signal processing” such as multi-mic beamforming, echo cancellation, and even low-power wake word detection (critical for battery-powered portable devices). The ultimate purpose of front-end processing is to improve the user experience, and critical to that experience is improving recognition accuracy of the ASR service, be it from Amazon, Google, or others. Vendors such as Cirrus Logic provide audio and voice solutions to help OEMs create products that sound great and respond reliably to voice commands, regardless of backend service. These include ICs and software for mic capture, front-end processing and loudspeaker playback.
What Affects Audio Performance?
Improving the quality of the voice signal sent to the cloud is not a question of simply adding more microphones. Three factors govern the input quality: the acoustic environment, the hardware design of the playing-and-listening device, and the digital signal processing applied to the microphone signals.
The acoustical environment is a given, and largely beyond the control of the designer. The hardware design and signal processing code employed, however, are implementation choices where clever investment can pay dividends.
What Do Users Want to Do with Smart Loudspeakers?
If you’ve used a speech recognition system, you’re familiar with the challenges of using voice control in noisy environments or from a distance. These include:
• Getting the device’s attention quickly and reliably
• Waking the device in noisy environments
• Waking the device from across the room
• Interrupting the device when it is already talking or playing music
• Getting the device to understand your request and do the right thing
Smart speakers come with additional requirements:
• Fantastic sound—clear, balanced, and as loud as desired
• Good performance as player and listener in a variety of room locations
• Long usage time before re-charge, if portable or battery-powered
• Physical appeal and the best audio performance possible for the size
• Appropriate mix of voice and physical controls; audible and visual feedback
• Easy pairing or setup with other devices and cloud services
• Stereo and multi-speaker synchronization
The Acoustical Environment
A smart speaker mic signal is degraded by four main physical factors: noise, distance, reverberation, and echo (see Photo 1). These interact, and the ultimate result is that the microphone signal contains a mix of desired talker signal and undesired signals (distortion and additive noise) collectively called noise. A design goal is to improve speech recognition accuracy by reducing the undesired part and allowing the desired speech to pass undisturbed.
• Additive Noise: Sources can include voice-like noises such as office chatter and TVs, sharp noises (e.g., clattering dishes or dogs barking), and steady background noises such as air conditioning, road noise and even the quiet hiss of the electronics itself. Some noises come from a particular direction, like the radio in the corner, while others, like the hum of a refrigerator, are diffuse and permeate the room.
• Distance: Talker-to-device distance is critical as sound intensity diminishes with the square of the distance and since sound power radiates into the room like an expanding sphere. Doubling the distance from 1 m to 2 m reduces the speech signal intensity by a factor of four, but the level of the diffuse room noise at the mic stays constant. Physics is unkind here. Moving from a hands-free distance of 1 m to a “far field” distance of 4 m in a living room is a reduction factor of 16, or a 12 dB SPL loss. In short, the signal-to-noise ratio (SNR) decreases very quickly as the talker moves farther from the mic.
• Reverberation: Sound waves are reflected by surfaces in the room like walls, floors, and furniture and arrive at the mic at slightly different times. The mic picks up a combination of the talker’s voice propagating along a direct path to the device and thousands of reflections from every surface in the room, collectively called reverberation. As talker-to-mic distance increases, the signal mix shifts from mostly direct voice plus a little reverberation, to a signal containing a good deal of reverberation and very little direct voice. This is known as the Direct-to-Reverberant energy ratio (DRR) and it decreases with increasing talker-to-mic distance. Just imagine … a smart speaker hears the world like you hear a phone call to a person talking into a speakerphone from across the room! Anything we can do to improve this will help all voice recognition engines, whether local or cloud based.
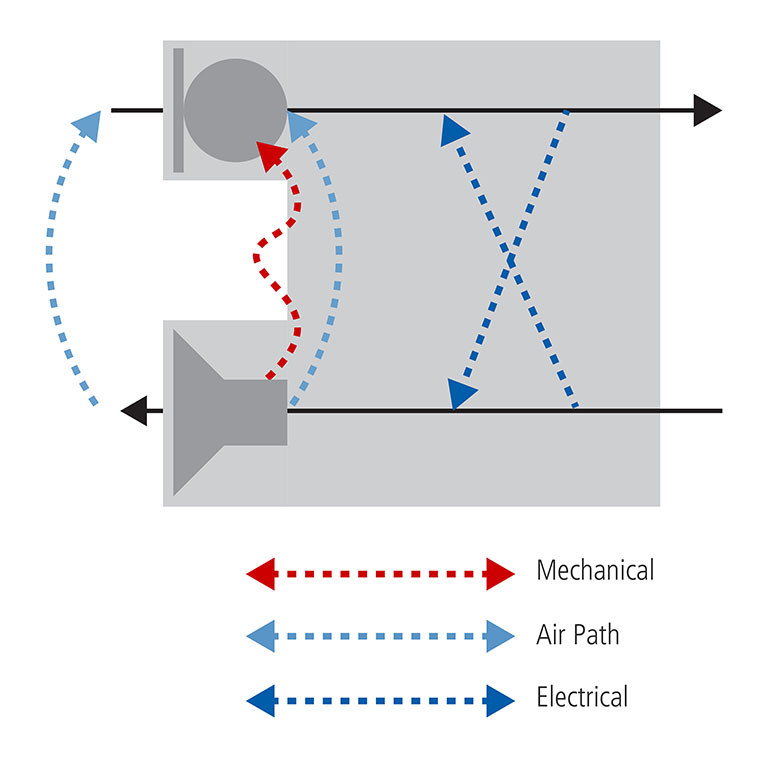
• Echo: Echo is leakage of the loudspeaker output signal, the music or speech that the device is playing out into the room, back into the device’s own microphone and ultimately up to the speech recognition engine in the device and/or cloud. It occurs through the air via acoustic reflections mentioned earlier and is also conducted by mechanical vibrations through the device structure.
How do these acoustic factors impair accurate speech recognition? Recall our major use problems: “wake word detection” and “command recognition.” Respectively, getting the device’s attention from a distance, and in noisy environments, and “barge in” or getting attention when the device is already speaking or playing music.

Wake-Word Detection
Reliable wake performance is made difficult by noise, distance, and reverberation. Design cues such as LEDs and video screens may help—anything that motivates the talker to face and directly speak to the device and stand as close as possible is helpful. However, the design may require 360° pickup and we cannot control the talker distance. Therefore, we need a way to reduce noise and reverberation.
Beamforming is a spatial noise reduction method based on mic arrays that can effectively focus or point the mics toward the talker direction while diminishing signals arriving from all other directions, which we know are mostly noise or reverberation. This has the net effect of improving the SNR, far beyond what can be captured with a single omnidirectional mic.
These techniques are collectively known as beamforming since an array of microphones is used to derive a single signal, which acts like a single magic microphone with a pickup pattern that is highly directional and steerable like a beam from a flashlight.
Beamforming is a term that covers a wide variety of techniques, including fixed and adaptive beams, various numbers of microphone elements (typically 2 to 8 for smart speakers), array geometries (typically points distributed on a circle or half-circle for 360° or 180° use) and processing sophistication. A related process to multi-mic beamforming is Direction of Arrival (DoA) estimation. The direction of the device’s “beam of attention” is relayed to the user by means of LED lights, and provides valuable feedback to the user to move closer, raise his voice or repeat the command.
There is another, more familiar type of noise reduction processing in which steady noises such as computer fans are estimated and subtracted, after the fact. However, ASR engines do not like aggressive noise reduction (NR).
Although moderate amounts sound like an improvement to human listeners, speech recognition accuracy is generally better if this type of ambient noise reduction is turned off. In fact, Google Home guidelines recommend disabling mic path NR. Since ASR engines are trained on noisy speech, ambient noise is basically invisible to the ASR and the artifacts of aggressive NR are a net hindrance to machine recognition.
Additional wake detection design issues are latency, and in the case of portable products, battery life. It is preferable to perform wake-word detection locally on the device as this gives a much faster response to the user, rather than endure a needless up-and-down interaction with the cloud, which could raise privacy concerns. However, this requires intelligence on the device, which has a power-consumption cost for portable devices. A solution is to use dedicated silicon for wake detection (and beamforming) that can function in a low-power mode, avoiding the need to run the main processor at full pace in the long breaks between control interactions.
Barge-In Performance
To interrupt a device when it is playing music, for example, all the previous difficulty of waking from a distance in a noisy environment is now compounded by echo. Echo refers to the problem of loudspeaker output signal leaking into the device’s own microphone. This leakage is acoustic as the sound waves bounce off the walls in the room and are reflected back into the microphone, and also are transmitted directly to the mic as the housing of the device vibrates with the output signal (see Figure 1).
This is an old problem with speakerphones, but the intensity is worse here because music playback can be much louder. Have you ever tried to interrupt a person who is shouting? Echo is mitigated by a DSP technique called Acoustic Echo Cancellation (AEC). Without AEC, there is little hope for the device to understand commands, as the user’s voice signal is impossibly corrupted with the outgoing music signal. The AEC task grows more complex and expensive as the number of loudspeakers increases (e.g., mono to stereo to surround) and the number of microphones increases. It becomes more difficult as the volume of the music is increased as there is simply more echo to start with. Louder music can cause various nonlinear distortions in the loudspeaker device itself, which creates an unsolvable math problem in the AEC.
The effectiveness of AEC, and hence barge-in performance, is improved by minimizing mechanical coupling between loudspeaker transducers and microphones in the hardware design (see Figure 2). Improving isolation and choosing high-quality transducers and proper mechanical design prevents buzzing and nonlinear output distortion. Modern amplifier chips such as those from Cirrus Logic include smart techniques for limiting distortion in smaller transducers by limiting the excursion of the diaphragm.
Sounds Good, Good Listener
There is a direct correlation with how “good” a system sounds (audio quality) to its ability to respond. The ability to interrupt a voice-enabled device during playback depends on the AEC capabilities, as well as the playback system. If loud playback has low distortion, it will not only sound good to you, but to the AEC, which must cancel out the playback so it does not interfere with the device hearing you call out the wake word.
Therefore, how well a digital device works and plays music will also be a direct function of how much distortion comes from the speakers. Cheaper speakers tend to result in poorer quality audio and higher distortion playback when the volume is turned up. Technically, the playback system can never be better than its digital-to-analog converters (DACs). For example, Cirrus Logic includes a smart codec with integrated high-fidelity DAC in its Voice Capture Development Kit for Alexa Voice Service devices (see Photo 2). This, along with embedded voice control algorithms, will enable OEMs to create products that both sound great and respond reliably to voice commands.

Lower Power Designs Will Drive New Portable Devices
As the use of voice-response smart speakers grows, new audio and acoustic technology will improve performance and pave the way for new, innovative applications. Savvy buyers will look beyond the number of microphones. They will look for high-quality audio and portability with long battery life as determining factors when purchasing next-generation voice-enabled smart speaker devices.
Better acoustic technology, such as AEC, noise reduction, and low-distortion playback, will improve barge-in performance so that voice services can hear and understand you better. Another key benefit to the advanced audio technology will be higher quality audio that will also improve the overall listening experience.
New development kits with advanced audio functions are making it easier for smart speaker OEMs to develop this next generation of innovative designs and devices. Device OEMs won’t have to be acoustic experts in audio design to gain the improved functionality, performance, and features that come from improved audio capabilities. OEMs will also benefit from new lower power high-performance semiconductor design. For example, Cirrus Logic solutions use as much as 80% less power than others. This will free OEMs to design innovative new portable applications for smart speakers that provide amazing new user experiences. aX
This article was originally published in audioXpress, January 2018.
About the Author
Kevin Connor joined Cirrus Logic in 2017 in a technical marketing role where he builds prototypes and supports customers of Cirrus Logic’s Smart Home solutions, including voice processors, embedded software and audio tools. He has previously worked as a researcher and DSP developer at BlueJeans Network, Cisco Systems, and Nortel Networks specializing in voice-over-IP, conferencing, networking, voice quality measurement, and monitoring. Kevin is a member of the Audio Engineering Society (AES) and enjoys recording, electronic music, and restoring vintage synthesizers.
Resources
* Global Market Insights report: https://www.gminsights.com/industry-analysis/smart-speaker-market



