


From an industry leader in Automatic Speech Recognition, Speechmatics is now working towards Autonomous Speech Recognition (ASR) using the latest techniques in machine learning. By introducing self-supervised models, the company says its latest engine is “a huge breakthrough” that takes accuracy to the next level.
The Cambridge, UK-based company has pioneered self-supervised learning technology that is claimed to reduce speech recognition errors for African American voices by 45% versus Amazon, Apple, Google, and Microsoft. Based on datasets used in Stanford’s “Racial Disparities in Speech Recognition” study, Speechmatics recorded an overall accuracy of 82.8% for African American voices compared to Google (68.6%) and Amazon (68.6). This level of accuracy equates to a 45% reduction in speech recognition errors – the equivalent of three words in an average sentence.
“It’s critical to study and improve fairness in speech-to-text systems given the potential for disparate harm to individuals through downstream sectors ranging from healthcare to criminal justice,” states Allison Zhu Koenecke, lead author of the Stanford study on speech recognition.
For its new Autonomous Speech Recognition software, Speechmatics claims to be able to deliver similar improvements in accuracy across accents, dialects, age, and other sociodemographic characteristics.
“Up until now, misunderstanding in speech recognition has been commonplace due to the limited amount of labeled data available to train on. Labeled data must be manually ‘tagged’ or ‘classified’ by humans which not only limits the amount of available data for training but also the representation of all voices. With this breakthrough, Speechmatics’ technology is trained on huge amounts of unlabelled data direct from the internet such as social media content and podcasts. By using self-supervised learning, the technology is now trained on 1.1 million hours of audio – an increase from 30,000 hours. This delivers a far more comprehensive representation of all voices and dramatically reduces AI bias and errors in speech recognition,” the company details.
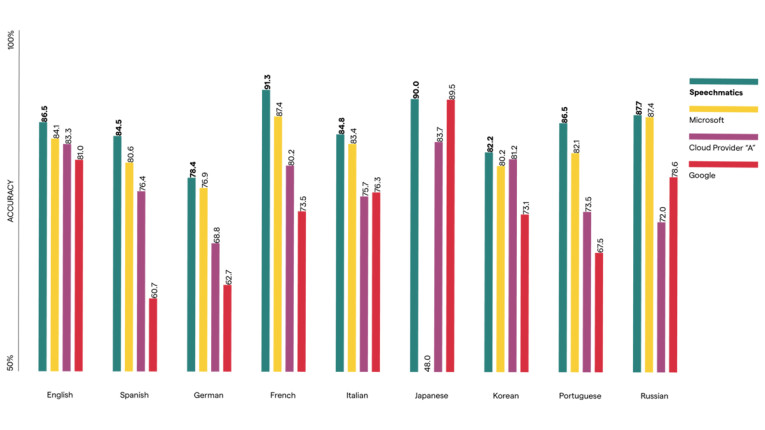
Speechmatics also claims to outperform competitors on children’s voices – which are notoriously challenging to recognize using legacy speech recognition technology. Speechmatics recorded 91.8% accuracy compared to Google (83.4%) and Deepgram (82.3%) based on the open-source project Common Voice.
Detailing the underlying research for Autonomous Speech Recognition, the company explains: “When it comes to technological advances in speech recognition, the lack of availability of audio data has slowed down progress. Automatic Speech Recognition has always relied on consuming large quantities of data from a narrow set of speakers. This is typically achieved through the use of human-labeled data, such as audiobooks.
“For years, speech recognition systems required human input on a vast scale. Be that scraping and processing data, building separate models for word pronunciations, or manually running various stages of neural network training. These processes took time and were often costly. Manually labeling huge amounts of training data has always been one of the major bottlenecks for improving Automatic Speech Recognition.”
The company’s Autonomous Speech Recognition method leverages the diversity of the Internet to better understand every voice regardless of accent, dialect, age, gender, or location. Text and unlabeled audio are continuously scraped from the Internet to be used when training the Language Model and the self-supervised model respectively. The acoustic model requires labeled audio data as it is trained in a supervised fashion so this data cannot be continuously collected.
To process the data, Speechmatics uses self-supervised machine learning, combined with autonomous data collection for continuous learning, autonomous pipelines to handle the complexity of training and deployment, and accessibility features. For readability and accessibility, the company uses Neural Punctuation, Inverse Text Normalization, and Diarization in its software. “Without complicating things too much, the first adds punctuation, the second helps with formatting and the last helps identify who’s speaking,” they explain.

“We are on a mission to deliver the next generation of machine learning capabilities and through that offer more inclusive and accessible speech technology. This announcement today is a huge step towards achieving that mission,” says Katy Wigdahl, CEO of Speechmatics.
“Our focus on tackling AI bias has led to this monumental leap forward in the speech recognition industry and the ripple effect will lead to changes in a multitude of different scenarios. Think of the incorrect captions we see on social media, court hearings where words are mistranscribed and eLearning platforms that have struggled with children’s voices throughout the pandemic. Errors people have had to accept until now can have a tangible impact on their daily lives,” Wigdahl adds.
Speechmatics offers free trials of the software and is ready to support companies and developers interested in their API. The company's technology, supporting multiple languages is already used in many different fields, with applications including voice translation, transcription and captioning.
www.speechmatics.com





