

With increasing user privacy concerns and regulations such as GDPR and HIPAA, sending voice recordings to the cloud is risky. Processing voice data on-device offers intrinsic privacy and compliance. Also, cloud computing is not an affordable option in the long term with the scale, while edge processing can tap into freely-available on-device compute resources to significantly reduce or eliminate cloud and connectivity expenses.
In certain use cases, milliseconds of delay matter, and relying on the cloud for voice processing necessitates continuous Internet connectivity. Picovoice offers highly accurate and lightweight speech recognition engines using deep neural networks trained in real-world environments. Picovoice based its work on the principles of transfer learning and hardware-aware training. Transfer learning enables zero-shot learning and removes extensive data collection and training per model, resulting in dramatically simplified product development, reduced time-to-market and more accurate voice models compared to the traditional methods relying on data gathering. Hardware-aware training optimizes voice models for the target platform, resulting in resource and power-efficient models even for stringent power consumption requirements.
Picovoice’s latest Speech-to-Text technology is described as a significant milestone. As the company explains, its new Picovoice Speech-to-Text service is private-by-design and 10x more cost-effective because it eliminates the cloud costs by bringing compute to data, instead of transmitting data to the cloud. This architecture also makes the service faster.
“Picovoice STT guarantees zero latency and reliability and prevents delays by cutting the dependency on connectivity to process voice data. Furthermore, new applications in certain industries such as healthcare and XR, where fickle Internet access can disrupt the user experience, and on battery-operated mobile devices, for which connectivity is a major source of battery drain, can be enabled with on-device processing,” they explain.
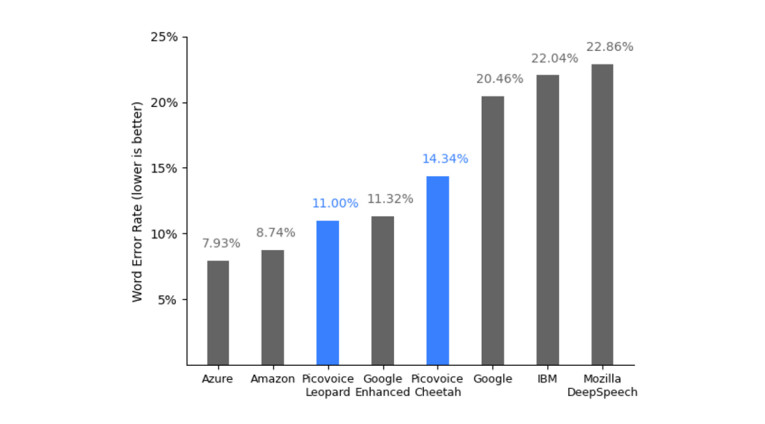
“Picovoice STT technology matches the accuracy of major cloud providers and can be customized on Picovoice Console to boost accuracy even more. For example, while a medical device company can customize the model with medical terms, a media company can do it with celebrity names,” they add.
Picovoice offers two Speech-to-Text engines: Leopard for non-streaming use cases and Cheetah for real-time transcription. Customers have the flexibility to use either one or both depending on use cases. To get started, Picovoice is offering to transcribe 100 hours of audio per month using Picovoice’s free tier. Either engines can be used for free. The starter tier for up to 10,000 hours/month transcription costs $999/month with a 75% discount to early-stage startups. Picovoice says that this is far more affordable than the average industry prices, between 6.5 to 21.5x more of what Picovoice charges for STTs.
Picovoice Speech-to-Text technology can be customized for several use cases, including but not limited to analyzing conversations such as customer call or meeting transcription, voice typing such as journaling, medical dictation or automating subtitles, and archiving purposes.

The base model of Picovoice Speech-to-Text technology comes with over 300,000 words in its lexicon. Picovoice Console enables organizations to train voice AI models with its type-and-train interface without writing a single line of code to add custom vocabulary to the base models.
For now, Picovoice Speech-to-Text is only available in English. As previously announced, the company intends to launch support for German, French and Spanish languages later in 2022, prioritizing further language support based on customer requests.
Picovoice specializes in edge voice AI, with cost-effective voice products that run across platforms including microcontrollers, mobile and desktop applications, modern web browsers, and servers. Picovoice provides out-of-box support for Linux, Windows, macOS (x86 and arm64), Android, iOS, Raspberry Pi (4, 3) and NVIDIA Jetson Nano. Picovoice enterprise tier customers can customize their packages with special platform support requests. Picovoice SDKs for Python, C, iOS, Android, Go, React Native, Flutter, Java, and .NET are available with the launch.

Picovoice also offers its own Wake Word Engine, Porcupine, which offers always-listening commands for rapid interactions without any friction, and Cobra, a Voice Activity Detection Engine, able to detect the presence of human voice within a stream of audio by differentiating it from ambient noises. The company's Speech-to-Intent Engine, Rhino, is a domain-specific natural language understanding (NLU) software that detects a speaker’s intent directly from spoken utterances without relying on a text representation. Finally, Picovoice offers a Speech-to-Index Engine, Octopus, able to index unstructured voice data to enable search. With its acoustic-only approach, Octopus boosts accuracy by removing the out-of-vocabulary limitation and problem of the competing hypothesis.
Picovoice technology is already used by various organizations for different use cases, including NASA, LG, Telenav, and Numina Group, among its customers. Picovoice recently donated AI models to Stanford’s Open Voice Assistant Lab.
www.picovoice.ai




