

The inspiration for this whitepaper comes from the World Health Organization's (WHO) recent World Report on Hearing, which shows that 1.5 billion people worldwide have some degree of hearing loss and 430 million people need rehabilitation services. Shockingly, less than 3% (on average worldwide) use hearing aids.
Can anything be done to change this?
For example, can True Wireless Stereo (TWS) earphones that use the same hardware components serve as over-the-counter (OTC) hearing aids? The answer is yes, if their software is upgraded with algorithms specifically tailored to the needs of the hearing impaired.

In audiology, hearing loss is quantified by measuring hearing thresholds for each ear at different frequencies but hearing loss is not a linear reduction in ear sensitivity that can be compensated for by a simple or even frequency-dependent linear sound amplification as shown in Figure 1. Instead, hearing loss is both frequency and sound level dependent, meaning that the degree and type of hearing loss can vary significantly depending on the specific frequencies and sound levels involved.
One of the main characteristics of hearing loss is "loudness recruitment," where the perceived loudness of sounds grows much faster for people with hearing loss than for those with normal hearing. As a result, the difference in sound level between "barely heard" and "normal" becomes very short for people with hearing loss, which can explain why they often have difficulty hearing others speaking to them in a normal voice.
This phenomenon has led to the development of multi-channel Wide Dynamic Range Compression (WDRC) for hearing loss compensation in hearing aids. However, hearing loss is a complex, non-linear, frequency-dependent, and cognition-related phenomenon that cannot be universally compensated by amplifying sounds. Nonetheless, proper hearing amplification can still benefit most people with hearing loss to some extent. Our goal is to make such amplification as efficient as possible.
Basic Digital Signal Processing in Modern Hearing Aids
All modern hearing aids are digital, i.e., analog electrical microphone signals are first digitized, then processed in the digital domain, and finally converted to an analog signal and reproduced through a receiver (loudspeaker).
The typical digital signal processing blocks of a high-end hearing aid are shown in Figure 2.
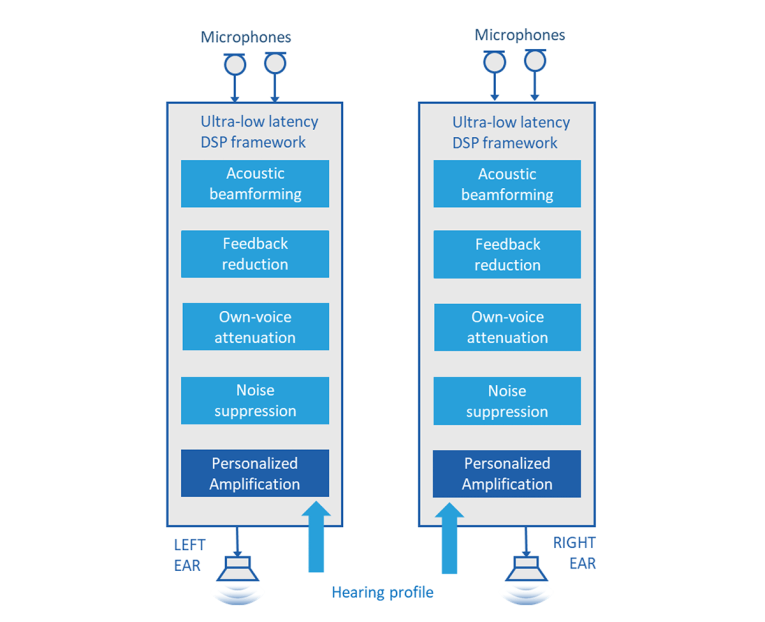
Most of the digital signal processing in hearing aids is done in frequency sub-bands. Digital signal processing is sequential, block by block. After all the processing is done, the full-band signal is resynthesized (combined) from the processed sub-band signals. In some cases, the processing blocks can receive sub-band signals from multiple sources and combine them into a set of sub-band signals. Acoustic beamforming is one type of this processing, shown in Figure 3.
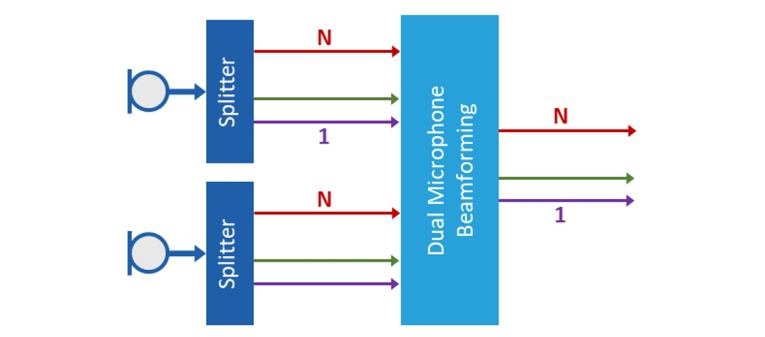
Splitting into and combining frequency sub-bands can be accomplished using various and well-known methods such as the short-time Fourier transform (STFT) or filter banks. Finite impulse response (FIR) or infinite impulse response (IIR) filter banks can be used, each having its own advantages and disadvantages. For example, IIR filter banks provide the shortest delays but are less suitable for implementing other algorithms such as adaptive beamforming, noise reduction, and others. When STFT is used for decomposition, the sub-bands contain complex numbers and are said to be processed in the "frequency domain."
The number of sub-bands, their frequency distribution, and overlap depend on the method of sub-band decomposition as well as a tradeoff between frequency resolution, processing delay, computational complexity, available data memory on a given chip, and other affected parameters.
Personalized Hearing Amplification
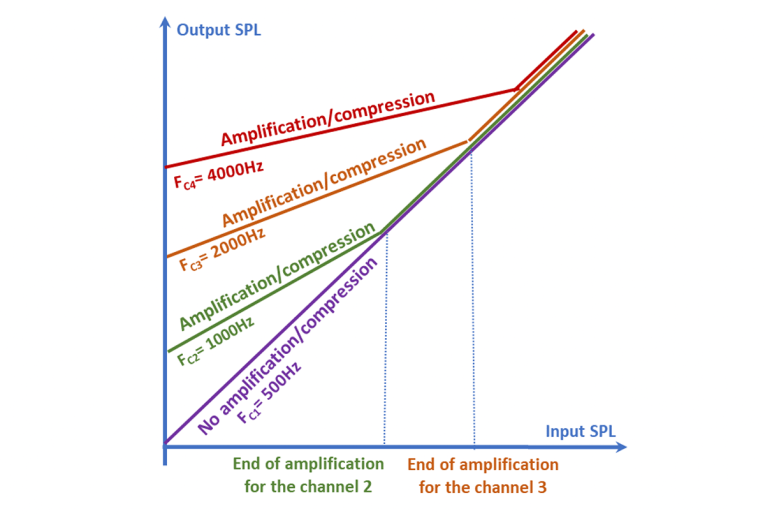
Modern digital hearing aids use multi-channel WDRC to achieve personalized amplification. This involves digitally amplifying and compressing the wide dynamic range of sounds heard by a healthy ear into a narrower range. As ambient sound increases, amplification is naturally reduced compensating for the loudness recruitment.
The channels are amplified/compressed differently according to a specific hearing loss. Each channel usually contains signal frequencies that correspond to a certain predefined frequency range and partially overlap. The channels can correspond to the frequency sub-bands one-to-one or combine several and even an unequal number of sub-bands, depending on the required frequency resolution. In practical implementations for hearing aids, the number of frequency channels can vary from 4 to 64.
In general, gain/compression parameters are set according to individual hearing thresholds measured directly or indirectly during a hearing test. Figure 4 illustrates the input/output characteristics of a four-channel WDRC corresponding to a high-frequency loss.
Most modern digital hearing aids are equipped with two microphones, positioned apart from each other (front and back) for acoustic beamforming. This technique generates a directional "sensitivity beam" toward the desired sound, preserving sounds within the beam while attenuating others. Typically, sounds from the front are preserved, while sounds from the sides and rear are considered unwanted and suppressed. However, different beamforming strategies can be applied in specific environments.
Acoustic beamforming relies on a slight time delay, typically in tens of microseconds, for sounds to reach the two microphones. This time difference is dependent on the direction of the sound and the distance between the microphones, as illustrated in Figure 5.
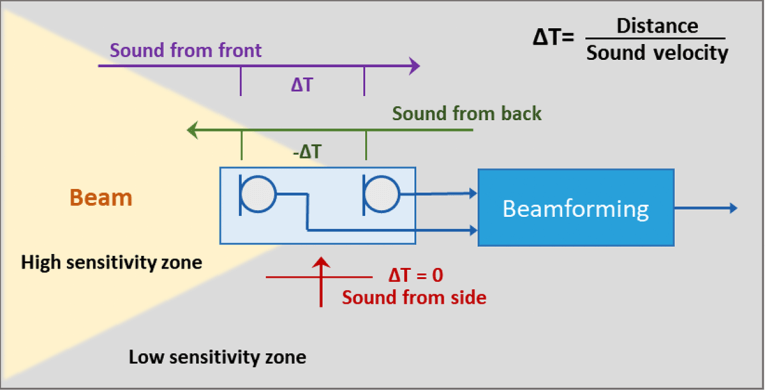
Front sounds reach the front microphone first, side sounds arrive simultaneously, and rear sounds reach the rear microphone first. Acoustic beamforming utilizes this time difference to create a variable sensitivity called a "polar pattern" or "polar sensitivity pattern" that is directionally dependent.
While sensitivity to front sounds stays consistent, sensitivity to sounds from other directions decreases with one angle having zero sensitivity. However, these theoretical polar patterns only apply in a free field and are not realistic in practical situations due to acoustic distortion caused by the user's head and torso.
Acoustic beamforming can be either fixed or adaptive. Fixed beamforming has a static polar pattern that is independent of the microphone signals and acoustic environment, making it easy to implement and computationally efficient. Adaptive beamforming, on the other hand, changes the polar pattern in real time to steer the null of the sensitivity polar pattern toward the direction of the strongest noise, optimizing array performance.
Adaptive acoustic beamforming can be implemented in either the full frequency band or in frequency sub-bands. The full band scheme optimizes an average performance with a uniform polar pattern across all frequencies in the hearing aid frequency range, which may not be optimal for individual frequencies. In the sub-band scheme, polar patterns are tailored to different frequency regions to optimize performance across frequencies. This can be more efficient for practical scenarios where noise comes from different directions in different frequency regions.
Noise Reduction
The primary concern of individuals with hearing loss is difficulty communicating in noisy environments. While acoustic beamforming can effectively reduce noise from specific directions, it has a limited ability to mitigate diffuse noise - noise that emanates from multiple sources without a distinct direction. Diffuse noise arises from multiple noise reflections off hard surfaces in a reverberant space, which further complicates noise directionality. For example, noise inside a car is often diffuse, as uncorrelated noises from various sources such as the engine, tires, floor, and roof are diffused by reflections off the windows.
Compensating for hearing loss with WDRC amplifies sounds that are below the user's hearing threshold, but it can also amplify noise and reduce the contrast between noise and the desired sound. Noise reduction technologies aim to mitigate these issues by suppressing noise prior to amplification by WDRC, thereby improving the output Signal to Noise Ratio (SNR).
Today, most noise reduction technologies used in hearing aids are based on spectral subtraction techniques. The input signal is divided into frequency sub-bands or channels, and the noise is assumed to have relatively low amplitude and be stationary across sub-bands, while speech exhibits dynamic spectral changes with rapid fluctuations in sub-band amplitude. If the average noise amplitude spectrum is known or estimated, a simple "spectral subtraction" strategy can be employed to suppress noise, as shown in Figure 6.
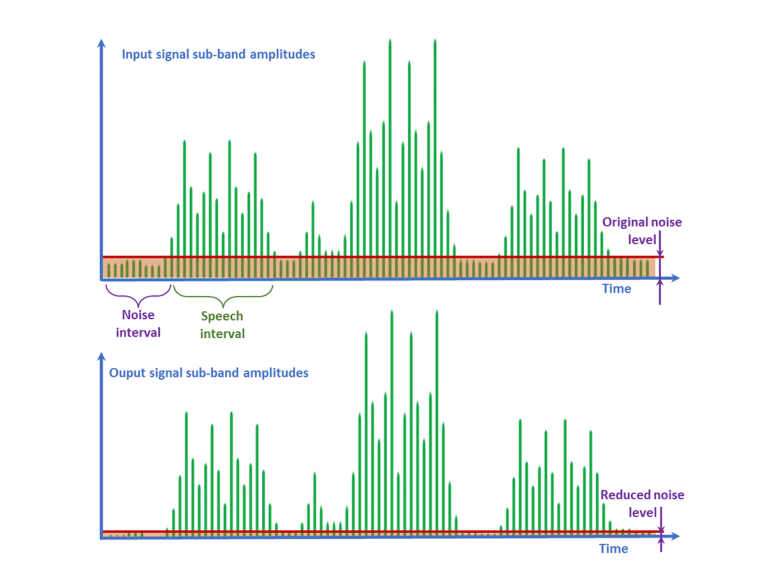
The upper plot illustrates the sub-band signal amplitudes of a speech in noise signal across different frequency sub-bands. The relatively stationary noise amplitudes are averaged by the red line, while the speech signal amplitudes are significantly higher. In the lower plot, the sub-band noise amplitude shown by the red line in the upper plot has been subtracted from the sub-band input amplitudes using the spectral subtraction technique, which is applied to all sub-bands. Finally, the output full-band signal is reconstructed using the same method used for splitting, with the noise effectively reduced.
Alango Digital Signal Processing for Hearing Aids
Alango Technologies has developed a full range of state-of-the-art DSP algorithms, software, and turnkey reference designs that can be scaled for various types of hearing enhancement devices, including OTC hearing aids, as well as TWS earbuds and headsets with amplified transparency and conversation boost.
Figure 7 displays the DSP technologies that are integrated into the Hearing Enhancement Package (HEP) developed by Alango.

While some of the technologies share names with those shown in Figure 2, they are based on Alango's proprietary algorithms, which have been refined based on our experience and feedback received from customers.
To select or design a DSP for hearing aids, one needs to compare different DSP cores and rank them according to certain criteria. The most important criteria are:
- Selection of available software algorithms
- Ease of porting unavailable algorithms
- Ease of debugging and optimization
- Possible power consumption to achieve the target uptime before recharging.
While we may have our own preferences, Alango partners with all major DSP IP providers and can deliver optimized solutions for them. Please, contact us for more details.
The Roadmap to the Hearing Enhancement
The possibilities for DSP technologies in the realm of hearing are endless. There are many other exciting opportunities to explore. For example, we could harness the power of neural networks to develop even more advanced noise reduction techniques, or leverage low latency wireless connectivity to create smart remote microphones with broadcasting capabilities. Additionally, active occlusion effect management and dynamic vent technologies offer promising avenues for addressing common hearing problems.
Beyond this, we can even consider innovative approaches like hearing sense substitution via tactile sense and real-time speech tempo manipulation for improved intelligibility. We are always excited to hear about your specific needs, ideas and interests. Please download the complete whitepaper for more details. We look forward to hearing from you!
The extensive version of this whitepaper is available for download here.
Contact information
HQ Address:
2 Etgar St., PO Box 62, Tirat Carmel 3903213
Israel
www.alango.com | www.alango-behear.com
Tel: +972 4 8580 743




