

Audioscenic developed a sound reproduction technology that allows for the real-time adjustment of spatial audio systems, providing an effective and natural ability to hear in three dimensions without the need for the listener to be constrained within a specific sweet spot.
Hearing in 3D
The human hearing system allows us to determine the locations of sound sources with exceptional accuracy: above, below, in front, and behind. The ability to hear in three dimensions is a remarkable feature of human auditory perception. Developed over the course of human evolution, our 360-degree, always-on hearing has enabled us to survive approaching threats and to communicate in complex acoustic environments.
When sound waves arrive at our head, they are modified by both the presence of the head itself and by the shape of the outer ears (the pinnae). These physical modifications are interpreted as sound localization cues by the brain, allowing us to associate a spatial position to every sound that we hear. There are two primary sound cues, along with additional secondary cues, that enable 3D hearing. The primary sounds cues are the Inter-Aural Time Difference (ITD) and Inter-Aural Level Difference (ILD).
The Inter-Aural Time Difference (ITD) refers to the time of arrival difference of a sound wave between the left and right ears. This is illustrated in Figure 1 — an incoming wave front will arrive at different times at the left and right ears, unless the sound source is situated within the axis of symmetry between them. A similar effect occurs with the Interaural Level Difference (ILD). Depending on the position of the sound source, a wavefront will be affected by the diffraction caused by the human head and will sound with more energy in one ear than the other.
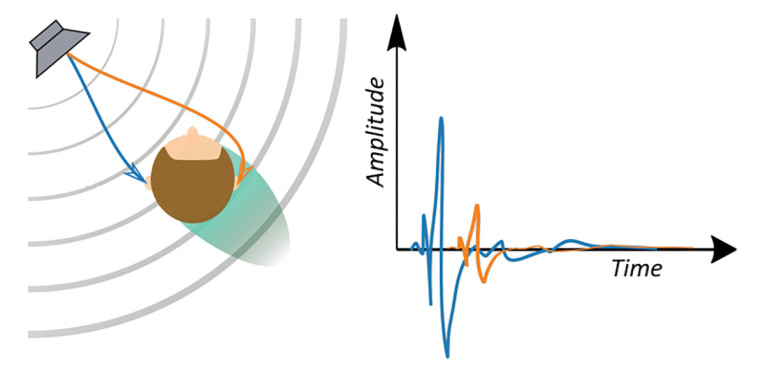
But how can we tell the location of sounds directly above or behind us? The answer lies in secondary sound cues provided by the asymmetric form of the pinnae and its inner structure. These complex anatomical shapes resonate at different frequencies in a direction-dependent manner, modifying the sound waves spectrum before they reach the tympanic membrane.
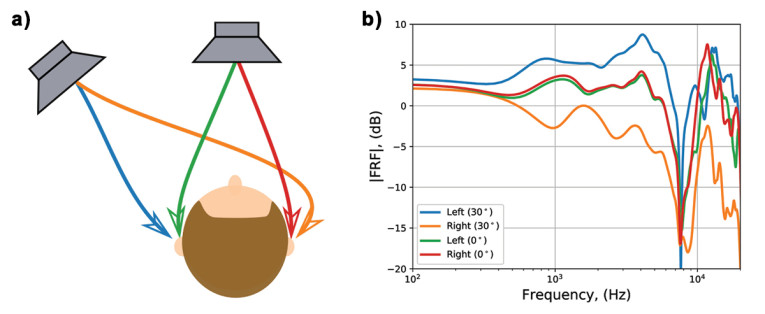
The result is that each unique direction of sound is associated with a spectral fingerprint. Spectral fingerprints are commonly referred to as head-related transfer functions (HRTFs), the transfer functions between a source at a given 3D position and our ears. The shapes of two HRTFs are shown in Figure 2 for two sound sources in the horizontal plane at 0-degrees (facing the listener) and 30-degrees (lateral to the listener). As shown in Figure 2, the two transfer functions for the source at 0-degrees are almost identical (except for some differences introduced in the measurement process). However, the transfer functions for the source at 30-degrees vary largely between both ears. These differences (or lack thereof) allow our brain to localize sounds in 3D space.
The effect of these cues is exploited by binaural recording techniques. In binaural recording, two microphones are employed to simulate our ears. When a binaural recording is listened to over headphones, the listener has the impression of being acoustically immersed in the place where the recording was made. Binaural recording techniques [1] are becoming increasingly common especially for content makers such as ASMR podcasters, and companies such as SonicPresence and 3Dio now offer binaural microphones at affordable price points for consumers.
Filtering with banks of HRTFs has become a standard for 3D sound synthesis and is widely used by the 3D sound and Virtual Reality (VR) industries. Furthermore, filtering with HRTFs allows conversion of any existent surround format (from stereo to 22.2) to binaural by creating virtual sound sources in directions that represent loudspeakers in those configurations. This allows full forward and backward compatibility with past and future spatial audio formats.
Similar principles have also been adopted by object-based audio formats such as Dolby Atmos, Windows Sonic, and DTS Headphone:X — all of which provide binaural encoding on the fly for channel-based content when played back on PC platforms. But, can we experience binaural audio without headphones?
3D Sound with Loudspeakers
The reproduction of binaural 3D sound with loudspeakers, also commonly known as crosstalk cancellation, was first explored in 1962 by Bishnu Atal and Manfred Schroeder [2], coinciding with early binaural recording attempts. Since then, and in parallel with developments in digital signal processing, the field of 3D sound with loudspeakers has evolved largely through the efforts of scientists, 3D sound enthusiasts, and innovative companies that have developed working solutions for delivering binaural audio through loudspeakers [3].
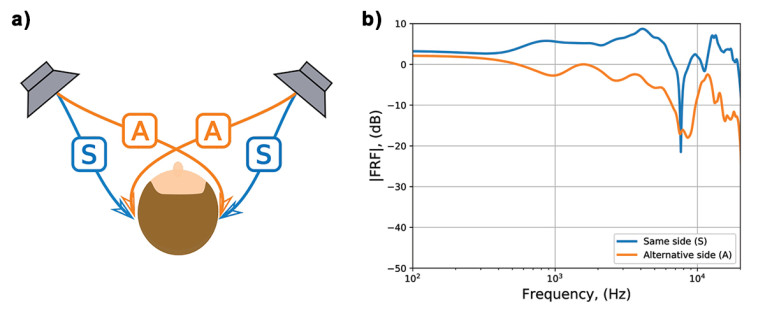
The 3D effect of binaural audio is achieved by independently feeding the left and right channels of the binaural signal, unaltered, to the left and right ears independently. This is natively guaranteed over headphones. However, when reproduced over loudspeakers, not only does each channel reach both ears, but it is also further colored by the additional HRTFs between each ear and the loudspeaker — this is known as crosstalk. The term crosstalk cancellation refers to cancelling the crosstalk that occurs when trying to reproduce a binaural signal with loudspeakers. This phenomenon is illustrated in Figure 3 — the HRTFs of a stereo loudspeaker system present a strong correlation between both ears (same side and alternate ear), especially at low frequencies. This will considerably distort a reproduced binaural signal, making it impossible to perceive 3D binaural cues as they were originally intended.
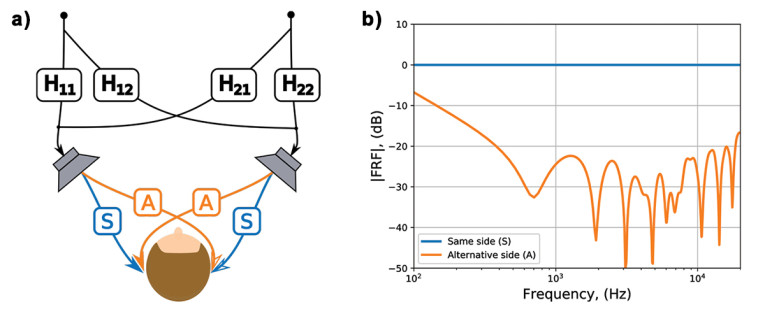
A crosstalk cancellation scheme, shown in Figure 4, consists of a set of digital filtering blocks that modify the loudspeakers’ input signals so that the left ear HRTF is delivered cleanly to the left ear and the right ear HRTF is delivered cleanly to the right ear. Ideally, the same side frequency spectrum should be flat and near unity, while the alternate side spectrum should have significantly reduced energy. This ensures channel separation between ears, along with clear reproduction of the binaural signal — accurately delivering the necessary localization cues as originally intended by the content creator. In other words, an effective crosstalk cancellation system creates “virtual headphones” at the listener’s ears so that a set of binaural signals is delivered cleanly and without distortion. By using such a scheme, it is possible to reproduce binaural audio with loudspeakers. This effect can be seen in the plot in Figure 4.
Although crosstalk cancellation systems can provide natural 3D sound with loudspeakers, there is an inherent problem: the fullness of 3D sound is only perceived if the listener is located in a precise location, or “sweet spot.” Amphi technology is designed to overcome this constraint, making 3D sound with loudspeakers achievable in everyday, common listening scenarios.
Enabling 3D Sound in Everyday Devices
End-user applications for 3D sound over speakers have been limited by the narrow sweet-spot problem: A listener can only experience high-fidelity 3D within a fixed position directly in front of the speakers. If the listener deviates even as little as 5cm from the designated sweet spot, the perception of spatial cues is dramatically decreased, as shown in Figure 5. Since viewers and listeners naturally shift position over time, a sweet spot that follows and adapts is needed. Audioscenic Amphi is listener position-adaptive 3D sound technology [4].
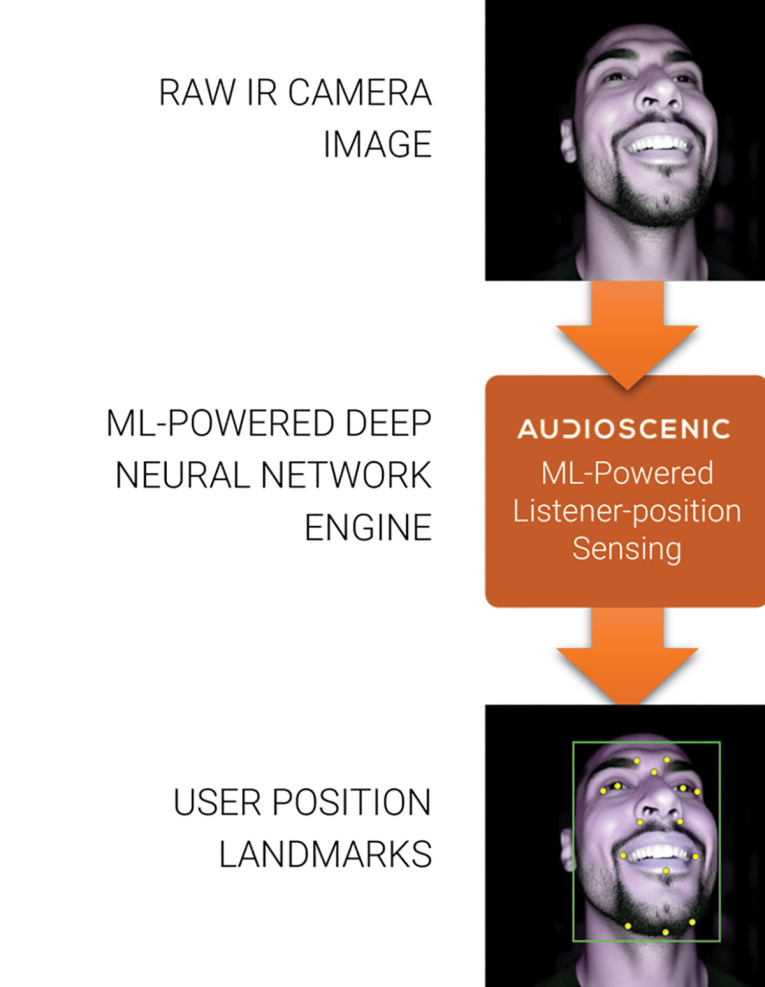
Listener-Position Sensing
At the core of Amphi is our Machine Learning (ML)-powered listener-position sensing system. Using a built-in camera or tracking sensor, Amphi continually detects the position of the listener’s ears relative to the audio device through head-tracking technology.
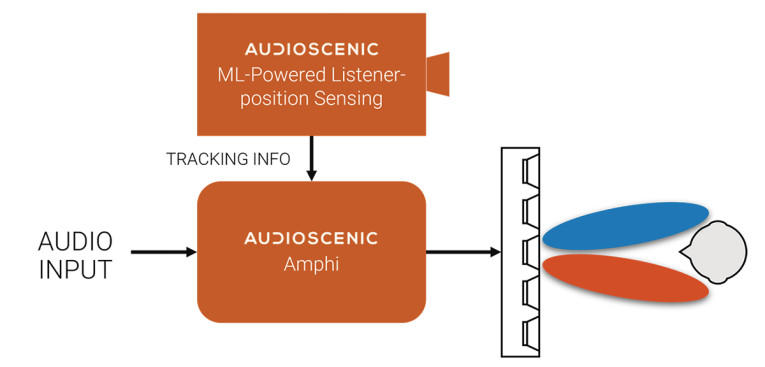
The ML-powered position sensing system only captures a set of position data landmarks, as shown in Figure 6. Amphi does not store video, images, or information about the user. When the listener makes a position adjustment, the real-time data is passed through a deep neural sound processor. The processed data enables the crosstalk cancellation sound beams to follow the user instantly as depicted in Figure 7. With position-adaptivity, binaural audio cues are delivered with maximum efficiency to the listener’s ears, ensuring that the listener is always receiving the best spatial audio experience.
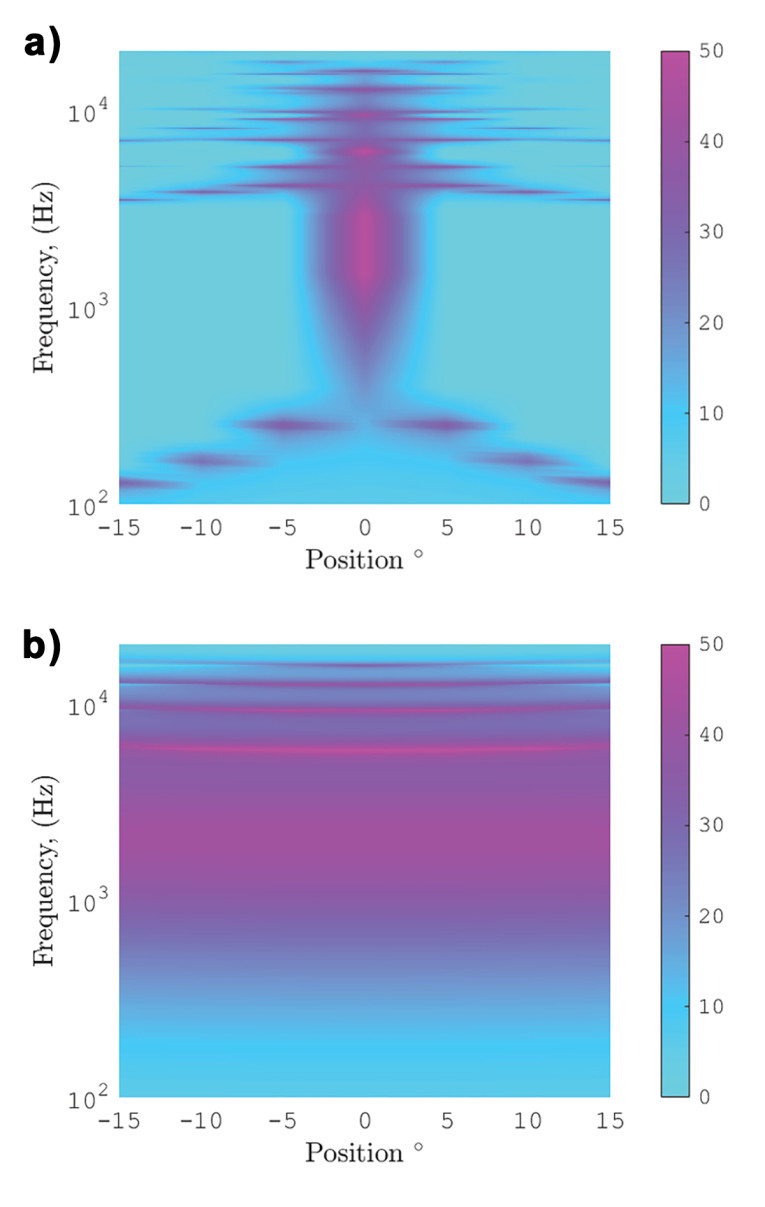
We can illustrate the sweet-spot adaptive capabilities of the Amphi technology by looking at the crosstalk-cancellation spectrum with position. The crosstalk cancellation spectrum is the pressure transfer function of the same side ear divided by the pressure transfer function of the opposite ear. The higher the crosstalk cancellation spectrum, the better that left and right binaural channels will be independently delivered to each ear resulting in better performance of a crosstalk cancellation system.
An example is shown in Figure 8 for a listener that is moving ±15 degrees in front of a loudspeaker array. Figure 8 shows that the non-adaptive system can only provide a substantial amount of crosstalk cancellation in positions between ± 4 degrees. Large variations of acoustic pressure occur beyond these positions along the horizontal axis. On the other hand, the Amphi algorithms allow for sweet-spot free reproduction, obtaining the same crosstalk-cancellation across the ±15-degree range measured in this example (consistent spectrum throughout the horizontal axis). There is no theoretical limit to the adaptation range for the Audioscenic Amphi technology.
Increased 3D Sound Performance and Naturalness
Accurate 3D sound reproduction is best achieved when the spatial audio system replicates physical cues as they are perceived in real-life environments. This is the case for binaural audio reproduction via headphones and via crosstalk cancellation systems.
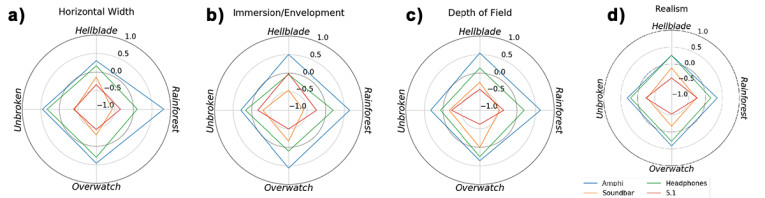
To demonstrate this, Audioscenic conducted a psychoacoustic behavioral experiment in which the subjective performance of an Amphi-enabled soundbar was compared to three spatial audio reproduction methods: a 5.1 system, headphones, and a commercial gaming soundbar. The experiment was run for a total of 15 listeners. For the test, various examples of immersive content were employed: “Ninja Theory Hellblade,” a video game with binaural 3D sound; “Unbroken,” a Dolby 7.1 Trailer with an aerial World War II fight scene; “Overwatch,” a video game with 7.1 sound; and “Rainforest,” a binaural recording of a tropical forest.
To analyze the different spatial audio reproduction systems, an attribute preference test was performed, wherein the experimenters were asked about various spatial attributes: horizontal width, immersion, depth of field, and realism. The results of the experiment are shown in Figure 9. It can be observed that the Amphi-enabled soundbar was preferred compared to the other systems for each of the attributes and overall.
Adjusting to the Needs
In theory, single-listener adaptive crosstalk cancellation can be delivered using a stereo loudspeaker system. However, research and experimental studies have shown that using more than two loudspeakers introduces many advantages.
Increased fidelity and audio quality: The use of more than two loudspeakers allows for better control of the loudspeaker array radiation efficiency across frequency bands. This means that a loudspeaker array can reproduce a more uniform frequency response and wider crosstalk cancellation spectrum compared to a system using just two loudspeakers [5].
Reduced room and reflection effects: The use of more than two loudspeakers reduces the total radiated power of a loudspeaker array and therefore minimizes the effect of room reflections and reverberation. This is important to achieving an optimal experience, as strong reflections reduce the perceived quality of the crosstalk cancellation system [6].
Amphi technology is configurable to work with various loudspeaker arrays. For example, in Figure 10 an Audioscenic gaming soundbar prototype and an Audioscenic studio reference system are shown and both systems share the same Amphi core algorithms.

Audioscenic Amphi Solution
Audioscenic aims to enable audio product manufacturers to incorporate Amphi technology to bring the maximum and most realistic 3D sound experience to their products. To this end, Audioscenic has developed a complete spatial audio software package for speakers and headphones, the Amphi Solution.
The Amphi Solution is the core of the Audioscenic position-adaptive 3D sound software. The Suite is a set of software libraries running in Windows OS and embedded devices, enabling the easy use of Audioscenic audio, listener-position sensing, and head-tracking technologies in common processor systems.
The Amphi Solution includes listener-position sensing software that can work with any computer-vision or wearable-based head-tracking system. Furthermore, the Suite features configurable convolvers for HRTF source selection and audio DSP functions (equalization, virtual bass enhancement, and dynamics controls) to enable easy integration, and optimized sound quality for manufacturers’ products.
For Windows OS products, the Amphi Settings Application end-user interface is available to provide user control for settings such as audio rendering modes, EQ, and listener-position sensing control.
Benefits of Audioscenic Amphi Technology
For manufacturers, Amphi Technology means the ability to eliminate the sweet-spot limitation, enabling 3D sound in everyday, common use-cases, from laptops and gaming monitors to soundbars and TV sound. As users are starting to become familiarized with spatial audio in headphones, the ability to enable a similar experience without headphones, in a simple speaker configuration is a clear selling-point.
Of course, Amphi technology is best suited to work with loudspeaker arrays. Compared to stereo speakers or multi-channel surround systems, loudspeaker arrays deliver better 3D sound and assure perfect crosstalk cancellation over the whole frequency range. Loudspeaker arrays are also more robust against the effect of reflections encountered in a normal room environment.
But Amphi technology can work with arrays using any number of loudspeakers and allows for a large degree of customization to different applications and needs (Figure 11). More importantly, Amphi technology can be used with any head-tracking system and can be used in software running in Windows OS or in embedded processors.

References
[1] “Hear New York City in 3D audio,” YouTube, www.youtube.com/watch?v=Yd5i7TlpzCk
[2] B. S. Atal and M. R. Schroeder, “Apparent sound source translator,” Patent, February 22, 1966, US Patent 3,236,949 https://patents.google.com/patent/US3236949
[3] J. Bennett, “Binaurality and stereophony in 60s/70s pop,” Joe Bennett Music Services, June 2017
https://joebennett.net/2017/06/30/binaurality-and-stereophony-in-60s70s-pop-iaspm2017
[4] “Audioscenic Technology Explainer,” YouTube https://youtu.be/NQ_9nyDuygU?feature=shared
[5] M. Simón, C. Berkeley, E. Hamdan, and F. M. Fazi, “A Robustness Study for Low-Channel-Count Cross-Talk Cancellation Systems,” Audio Engineering Society Conference: 2019 AES International Conference on Immersive and Interactive Audio, March 2019
[6] M. Simón, M. Blanco Galindo, and F. M. Fazi, “A study on the effect of reflections and reverberation for low-channel-count Transaural systems,” Proceedings of Internoise 2019, Madrid, Spain, 2019.
Resources
B. Bernschütz, “A Spherical Far Field HRIR/HRTF Compilation of the Neumann KU 100,” in AIA-DAGA 2013 Conference on Acoustics, 2013.
Dolby Laboratories, https://professional.dolby.com/categories/pc
DTS, “DTS Headphone X,” https://dts.com/anywhere
Predator Spatial Labs View 27, Acer Inc.
www.acer.com/gb-en/predator/monitors/spatiallabs-view-27
Razer Leviathan V2 Pro, Razer Inc.
www.razer.com/gb-en/gaming-speakers/razer-leviathan-v2-pro
SonicPresence, https://www.sonicpresence.com
This article was originally published in audioXpress, November 2024



