


“Sorry – can’t hear you—someone at the next table is talking really loudly.”
“Hang on, there’s a plane going over…”
“Just a minute, I’m going to a quieter room…”
Sound familiar? The number of phone and video calls we make is increasing all the time, so we are all finding ourselves saying things like this more and more often. Thanks to technology and to widespread network coverage, we can now make calls from almost anywhere, using our phone, laptop, or tablet. But that often means we are doing so in noisy cafés, on trains and buses, or perhaps while walking down the street. And, if we work in an open-plan office, we may have to contend with the background chatter from our colleagues’ calls and meetings. Our world has grown noisier, and although the human brain is very clever and can pick out the voice we want to hear even in a cacophony of competing voices and noise, it is still difficult for many of us to hear the voice we want to listen to as clearly as we would like.
Electronic devices, which also need to pick up audio signals clearly, have the same issue: In an increasingly noisy world, the signals reaching their microphones are a mix of the relevant voice, background noise, room reverberations, and other interference. This means the quality and intelligibility of the speech that the devices are designed to capture can be badly affected, leading to poor performance. Intelligible speech is crucial for a huge range of modern technology — not just the phones and computers we use for calls and VoIP, but also for conferencing, transcription, car infotainment, home assistants, and of course, hearing assistance.
Signal processing techniques (e.g., beamforming and blind source separation) can help—but they have different benefits and drawbacks. So which technique is best for which application?
Beamforming Uses
Audio beamforming is a technique that has been available for a long time, and it is one of the most versatile multi-microphone methods for emphasizing a particular source in an acoustic scene. Over the years, many different types of beamformers have been developed and they can be divided into two types, depending on how they work: data-independent or adaptive. One of the simplest forms of data-independent beamformers is a delay-and-sum beamformer, where the microphone signals are delayed to compensate for the different path lengths between a target source and the different microphones. This means that when the signals are summed, the target source coming from a certain direction will experience coherent combining and it is expected that signals arriving from other directions will suffer to some extent from destructive combining.
However, in many audio consumer applications, these types of beamformers will be of little benefit. Why? There are a couple of reasons.
The first has to do with the size of the array compared with the frequencies of normal speech. For delay-and-sum beamforming to do a good job, it needs the wavelength of the signal to be comparable with the size of the microphone array. The wavelengths in audio range from millimeters to meters and, from the physics of antenna theory, we know that the optimal microphone spacing is one quarter of the wavelength of the sound you wish to receive. The low frequencies of speech have a very large wavelength—measured in meters. This is why top-of-the-range beamforming conference microphone arrays are typically 1m in diameter and have hundreds of microphones, which allow them to cover the wide dynamic range of wavelengths. They can work very well but, of course, are very expensive to produce and are suitable for the business conferencing market only.
When it comes to devices designed for consumers, they usually have only a few microphones in a small array. In these use cases, the delay-and-sum beamformer really struggles as it is contending with the large wavelengths of speech arriving at a small microphone array. A beamformer the size of a normal hearing aid, for example, cannot give any directional discrimination at low frequencies — and at high frequencies it is limited in its directivity to a front/back level of discrimination.
Another problem relates to the way sound behaves. It does not move in straight lines: A given source has multiple different paths to the microphones, each with differing amounts of reflection and diffraction. This means that simple delay-and-sum beamformers are not very effective at extracting a source of interest from an acoustic scene. But they are very easy to implement and do give a small amount of benefit, so they were often used in older devices.
Over the years, many more advanced beamforming techniques have been developed and are now available. One of the most well-known adaptive beamformers is the minimum variance distortionless response (MVDR) beamformer. This tries to pass the signal arriving from the target direction in a distortionless way, while attempting to minimize the power at the output of the beamformer. This will have the effect of trying to preserve the target source while attenuating the noise and interference.
This technique can work well in ideal laboratory conditions but, in the real world, microphone mismatch and reverberation can lead to inaccuracy in modeling the effect of source location relative to the array. The result is that these beamformers often perform poorly because they will start cancelling parts of the target source. Of course, a voice activity detector can be added to address the target cancellation problem, and the adaptation of the beamformer can be turned off when the target source is active. This can perform as desired when dealing with just one target source but, if there are multiple competing speakers, this technique has limited effectiveness.
And, again, MVDR beamforming — just like delay-and-sum beamforming and most other types of beamforming — requires calibrated microphones as well as knowledge of the microphone array geometry and the target source direction. Some beamformers are very sensitive to the accuracy of this information and may reject the target source because it does not come from the indicated direction.
More modern devices often use another beamforming technique called adaptive sidelobe cancellation, which tries to null out the sources that are not from the direction of interest. These are state-of-the-art in modern hearing aids and allow the user to concentrate on sources directly in front of them. But the significant drawback is that you must be looking at whatever you are listening to, and that may be awkward if your visual attention is needed elsewhere — for example, when you are paying for your drink but talking to someone next to you in the line.
The BSS Route
Luckily, there is another way of improving speech intelligibility in noise — blind source separation (BSS). BSS is a family of techniques which has been the subject of scholarly articles and laboratory experiments for some time — but here at AudioTelligence we have developed BSS algorithms, which are successfully running on products in the real world. You can hear the difference between BSS and beamforming in this video.
How does BSS work? There is more than one way of performing BSS. Time-frequency masking estimates the time-frequency envelope of each source and then attenuates the time-frequency points that are dominated by interference and noise. At AudioTelligence, we prefer to use another method — linear multichannel filters. We separate the acoustic scene into its constituent parts by using statistical models of how sources generally behave. BSS calculates a multi-channel filter whose output best fits these statistical models. In doing so, it intrinsically extracts all the sources in the scene, not just one.
We chose to use this method (Figure 1) because it can handle microphone mismatch and will deal well with reverberation and multiple competing speakers. Importantly, it does not need any prior knowledge of the sources, the microphone array, or the acoustic scene, since all these variables are absorbed into the design of the multi-channel filter. Changing a microphone, or a calibration error arising, simply changes the optimal multi-channel filter.
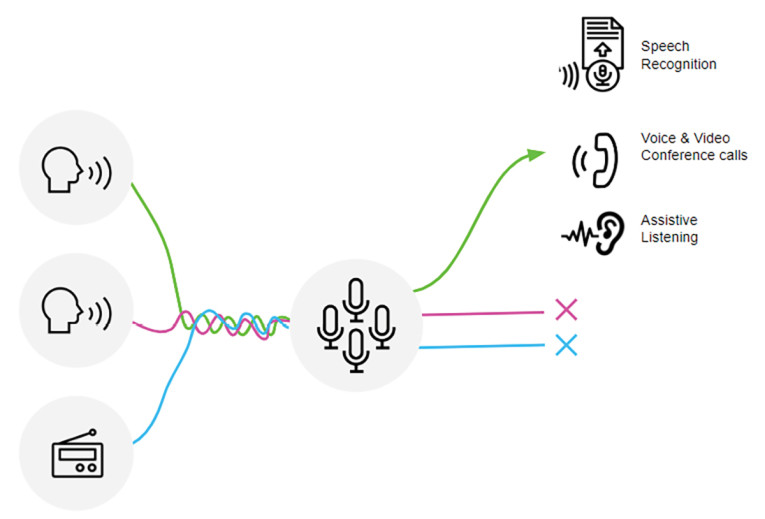
Because BSS works from the audio data rather than the microphone geometry, it is a very robust approach that is insensitive to calibration issues and can generally achieve much higher separation of sources in real-world situations than any beamformer. And, because it separates all the sources irrespective of direction, it can follow a multi-way conversation automatically. This is particularly helpful for hearing assistance applications where the user wishes to follow a conversation without having to interact with the device manually. BSS can also be very effective when used in VoIP calling, home smart devices and in-car infotainment applications.
Sounds easy? Not at all. Developing a BSS solution that works in real products, not just in the laboratory, is very hard — it has taken us years of research and experimentation to create, develop, and test our algorithms. The journey started many years ago, before the advent of the voice recognition revolution. I was working at CEDAR, a company specializing in audio restoration and dialog noise suppression.
We were looking for a long-term research project and identified audio BSS as a key technology to investigate. We predicted that the increase in compute performance and power within a 5- to 10-year horizon would allow the algorithms necessary for BSS to be implemented successfully, although it was not feasible with the state of compute performance at that time. We also identified several key problems that we felt we could solve using some of our proprietary know-how. In particular, we thought we could solve the sub-10ms algorithmic latency required by real-time hearing assistance applications, as well as improving both CPU and acoustic performance.
That decision led to 10 years of research and the creation, development, and testing of proposed solutions. We finally had one we were happy with, but CEDAR considered that turning our algorithms into a product would take the company in a new strategic direction and that it would be better for this to be done in a new company. And so AudioTelligence was born as an independent company — a colleague and I moved to AudioTelligence, and, together with the team we recruited, we have taken the solution from algorithms to actual products.
But BSS isn’t without its own problems. For most BSS algorithms, the number of sources that can be separated depends on the number of microphones in the array. And, because it works from the data, BSS needs a consistent frame of reference, which currently limits the technique to devices which have a stationary microphone array — for example, a tabletop hearing device, a microphone array for fixed conferencing systems, or video calling from a phone or tablet, which is being held steady in your hands or on a table.
When there’s background babble, BSS will generally separate the most dominant sources in the mix, which may include the annoyingly loud person on the next table. So, to work effectively, BSS needs to be combined with an ancillary algorithm for determining which of the sources are the sources of interest — we combine it with our conversational dynamics algorithm which dynamically follows those sources in a conversation.
BSS on its own separates sources very well, but does not reduce the background noise by more than about 9dB. To obtain really good performance, it has to be paired with a noise reduction technique. Many solutions for noise reduction use AI — for example, it’s used by Zoom and other conferencing systems — and it works by analyzing the signal in the time-frequency domain and then trying to identify which components are due to the signal and which are due to noise. This can work well with just a single microphone. But the big problem with this technique is that it extracts the signal by dynamically gating the time-frequency content, which can lead to unpleasant artefacts in poor signal-to-noise ratios (SNRs), and it can introduce considerable latency.
Enter AISO
At AudioTelligence, we wanted to develop a noise reduction technique to combine with our BSS, which worked well with multi-microphone arrays and did not introduce latency or artifacts. The result is our low-latency noise suppression algorithm which, combined with BSS in our AISO software solution, gives up to 26dB of noise suppression and makes our products suitable for real-time use. Hearing devices, in particular, need ultra-low latency to keep lip sync — it is extremely off-putting for users if the sound they hear lags behind the mouth movements of the person to whom they are talking. This is a difficult problem — but one which we’ve managed to solve. Despite the complex calculations performed, the underlying algorithms in AISO combined have a latency of just 5ms — which is essential for real-world use — and they produce a more natural sound with fewer distortions than AI solutions.
But when it comes to distinguishing speech in noise, is there an objective measure of performance? One which is commonly used is to measure the percentage of words correctly understood in different SNRs. At -5dB SNR (a typical family dinner), a top-of-the-range hearing aid typically improves speech understanding to 50% — and a top-of-the-range assistive listening device to 80%. Figure 2 shows the performance of the AudioTelligence AISO algorithms, illustrating an improvement of speech understanding from 5% to 98% at -5dB SNR.
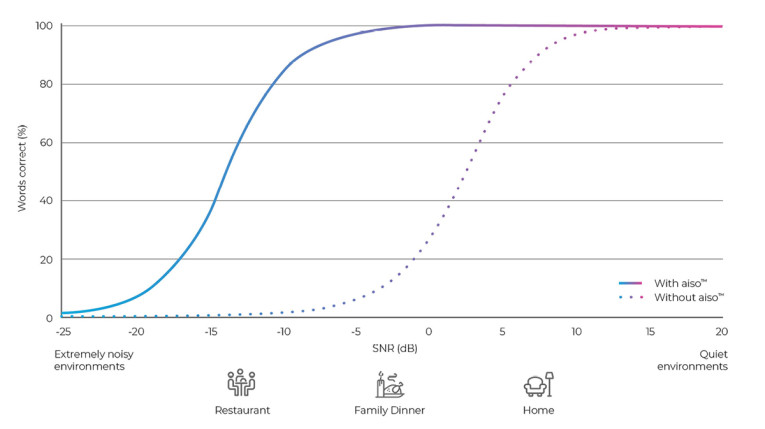
So, BSS can perform really well in increasing the intelligibility of speech in noise. But there is one issue we still have not discussed: echo. I think we have all occasionally experienced the huge irritation of hearing echoes from speaker phones and other devices, when the phone’s microphone picks up your voice from the loudspeaker. This echo can occur in other situations as well. The solution for the last 70 years has been to use an adaptive filter to try to cancel out the echo. Many different algorithms have been used, but they all work by trying to predict the echo from the signal driving the loudspeaker. The better they make that prediction, the better they can cancel the echo.
Today, thanks to the recent increases in compute power, more sophisticated signal processing techniques — such as recursive least squares and minimum mean square error — can be used. These algorithms are all forms of linear prediction, and they all struggle with nonlinear distortion. For modern acoustic echo cancellers it is these nonlinear distortions that limit the performance.
At AudioTelligence we needed to solve the echo distortion problem to ensure that our BSS could be used effectively where there is echo. The important property we use is that the distortion occurs mostly in the loudspeaker. This means that, to our BSS, it looks just like any other acoustic source. So, BSS will automatically remove the nonlinear distortion as an unwanted source. This doesn’t require any accurate modeling of the nonlinear distortion — we get this effect free as part of BSS.
This will work with most acoustic echo cancellation (AEC) algorithms. Our AEC is particularly powerful as it deals with multiple references such as 5.1 surround sound as well as acoustic path lengths of up to 125ms. It is also designed to preserve the relationships necessary for BSS to work effectively. This ensures that we remove as much of the linearly predictable part of the echo as possible while leaving the residual intact for BSS to perform its magic. The BSS then sweeps up any residual distortion.
Signal processing has come a long way since I started working in audio many years ago. There are multiple techniques from which to choose, all of which are becoming more sophisticated and complex. Selecting the right technique for your application requires consideration not just of the performance you need, but the situation in which you need the application to work, and the physical constraints of the product you have in mind. aX
This article was originally published in audioXpress, November 2022.
 About the Author
About the AuthorDave Betts is the Chief Science Officer at AudioTelligence. He has been solving complex problems in the field of audio for more than 30 years, and his experience ranges from audio restoration and audio forensics to designing innovative audio algorithms used in a huge number of blockbuster films. At AudioTelligence, Dave leads a team of researchers delivering innovative commercial audio solutions for the consumer electronics, assistive hearing, and automotive markets.



