The purpose of DaS AuReality is twofold: First, is the introduction of the concept of “Diffusion at Source” (DaS), wherein each frequency has its own unique, time decorrelated polar (TDP), sound field (elliptical in polar shape). Conventional speakers have time coherent polar (TCP) sound field (circular in polar shape). Second, is to transform the sound field produced by time coherent, individual-driven piston radiators, into a dynamic, dual-state, constant power, acoustic sound field.
In this dualistic behavior, either the acoustic sound field is acting like a perfect point source (harmonically driven), or it acts like a rotating sound field, think Leslie Loudspeaker, whenever there is a sudden change in the signal (the step response). By combining these dual-properties, DaS AuReality acts as an acoustic redefining sound reinforcement/reproduction tool, capable of producing “true reality” like sound fields, in any listening room, at all scales of application.
DaS AuReality has evolved out of work known as “Acoustic3D” from an Australian-based company. DaS AuReality is now being commercialized by Vastigo, Ltd. (Vastigo.com), headquartered in Singapore. Vastigo is offering licensees for the DaS AuReality technology into its many market application segments, which include virtually all speaker applications. The technology is backed up by a comprehensive multi-generation and geographical market patent folio.
Understanding the Relationship Between Diffusion and Time
To understand how DaS overcomes “listening room acoustic challenges,” the reader will need to understand the relationship between “diffusion” and “time,” when used in an acoustical context. A simple way to put it is: Diffusion is energy that has completely lost time information. Here, I will draw upon concepts used in auditorium acoustics and psychoacoustics. An “event” is a perfect descriptor for explaining the perception of a listening room acoustic. A new event is described in auditorium acoustics as a sudden change in the energy envelope by 10dB or more, indicating a sudden, but meaningful change in energy in the room.
This sudden change of energy will trigger the listener’s perception system to localize the sound source and contextualize it in 3D space. In practice, this event could be someone saying a word, it could be a musical note, or a percussive strike on a drum! These events give a perfect opportunity for the human brain, via the mechanisms available in the anatomy of the inner ear, to hear the early reflection patterns of a listening room, from which it builds a perception of the sonic environment surrounding them.
In Figure 1, we see an auditorium acoustician’s representative diagram of the early reflection behavior of the non-ideal listening room (Figure 1a), and then the more ideal, “optimized” listening room (Figure 1b). Let’s use the word “Event” as the new acoustic sound source in this model. To the human brain, the word Event has meaning! It is a learned pattern in our psychology.
In the non-ideal listening room (Figure 1a), through a time coherent polar loudspeaker, the original word “Event“ is reflected back to the listener at small time delays, and at ever reducing levels. The levels are reduced by the reflection process off the walls, floor, ceiling, and other surfaces where acoustical energy is absorbed from the wave front. The time delays are purely due to the difference in the pathways that the wave front travels, in finding its way back to the listener. The absorption of energy over time from the reflection process is quantized as reverb time!
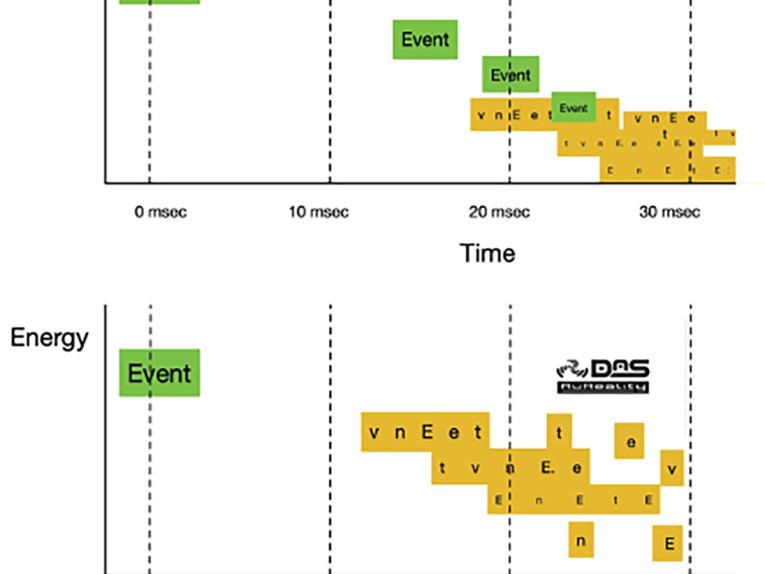
In a non-ideal listening room, the word “Event” will be heard several times, subliminally, in the early reflection patterns. Assuming the walls are purely flat they will create specular reflections. This means the reflection energy is pretty much still the word “Event.” It is just time delayed, and slightly reduced in energy, and perhaps missing a little bit of the top end.
Whenever the word “Event” can be clearly heard subliminally in the listening room acoustic, I will indicate it with a green background. In the top image, we can see five clearly repeated and audible “Event” of the listening room acoustic over the first 30ms. The first repeat arrives at around 15ms. All of this is made possible as the loudspeaker source is time coherent polar. Every direction has the same sound. The human ear and brain will process this clearly repeated pattern and allocates various perceived acoustic qualities, depending on the arrival time and energy of these early reflections. Almost always, the perceived quality will be a negative comparison to the ideal listening room.
What is well known in auditoria acoustics is the specification for the “holy grail” for listening room design: it is what is shown in the ideal room (Figure 1b). In this ideal listening room scenario, the only time you hear the word “Event” is directly from the source and never again. You want all the reflected energy to be diffuse, that is, to lose all of its timing information.
The DaS technology delivers this diffuse sound at the speaker source, making the room boundaries and contents irrelevant to the sound energy in the room. The diffuse sound hits the walls and other barriers and collapses into itself as decorrelated energy waves. The original sounds are heard crystal clear without compromise. In the context of the metaphor, instead of the reflected energy being the word “Event” again, can you somehow make the reflected word be “vnEet”—that is, move the order of the letters around (this is a metaphor as the timing is faster than the length of spoken vowels). Or better still, can you spread out the reflected word over time, so that it becomes twice as long in time (i.e., “v n E e t”? This is called a non-specular reflection. The reflection looks nothing, or very little, like the direct word “Event.” I’ve indicated non-specular reflections in the diagram with amber backgrounds.
To take this concept even further, can you somehow make the other early reflections look nothing like either “Event” or the first reflection “v n E e t”? If you can do this, the human brain will not hear these subliminal repeats of the direct word, and will thus not allocate any negative listening room acoustic attributes to the sound quality.
Arguably, if you can do this well enough, the human brain may not even acknowledge that it’s in a room without the presence of early specular reflections! The absence of subliminal repeats of these “events” deprive any opportunity for the human brain, via the mechanisms available in the anatomy of the inner ear, to assemble the early reflection patterns of a listening room to build a perception of the sonic environment surrounding them. Using DaS technology, we have just eliminated the “listening room effect” from the playback!
In the non-ideal listening room, specular reflections will eventually become non-specular reflections! This is just the nature of multiple generation reflected energy breaking down. In the non-ideal room (Figure 1a) eventually the amber background energy becomes dominant, but typically only after the acoustic energy in the room has significantly diminished. Think toward the tail end of a sound — this is generally too late to be useful!
In the ideal listening room scenario (Figure 1b), we have amazingly managed to get every reflection to be non-specular. That is, not a subliminal repeat of the direct or any other reflected sound! Without the DaS technology the only way to achieve the ideal listening room is extreme room treatment as shown in Photo 2 [1]. The horizontal plane, defined by the listener’s ears in the ideal mixing position, has been broken up using physical acoustical diffusors (white stalactite looking structures) on practically every horizontal surface in this the room. This design sets out to achieve the ideal room acoustic as defined by Figure 1b. It still misses a lot of surfaces including the complete floor and portions of the walls and ceiling.

The same listening result sought in Photo 2 can be achieved very simply through DaS, but far more efficiently, without any physical changes whatsoever to the listening room. I’ll explain how! If we can get the sound field from the loudspeaker to leave, at every frequency, at every polar angle, at a different phase angle, we will effectively achieve exactly the same listening experience result as has been achieved in Photo 2. But, at considerably less effort and cost, and without any room surface treatment!
The DaS acoustical algorithm used in the device results in a loudspeaker with a constant power in all directions in the polar plane. The number sequences used have the unique property that the Fourier coefficients are equal in all directions. The Fourier transformation does not specify the exact location in time of the signal within the Fourier Window. The key difference to conventional loudspeakers is that the signal “timing/phase” is “variable” in the polar plane. Each frequency has its own unique “flapping” motion releasing variable polar delayed acoustic energy into the listening room, at different polar angles. The result is a completely de-correlated sound field in every polar direction (i.e., no two directions are copies of each other).
Harmonically Driven Behavior (DaS)
DaS uses constant power with TDP sound fields. “Correlation” is the same as “specular” reflection wherein both the direct and reflected energy are substantially the same in shape. “Decorrelated” is the same as “non-specular” reflections wherein the reflected energy has nothing, or very little to do with, the direct energy.
We have used COMSOL to build simulations of DaS sound fields. Figure 2 shows a conventional TCP loudspeaker on the left and a DaS TDP loudspeaker on the right. For the sake of simplicity, we used a harmonically driven source containing three frequencies of equal amplitude — 9kHz, 11kHz, and 15kHz. As Dr. Toby Gifford very eloquently puts it, “looks like one half of the vinyl record got left in the sun!”
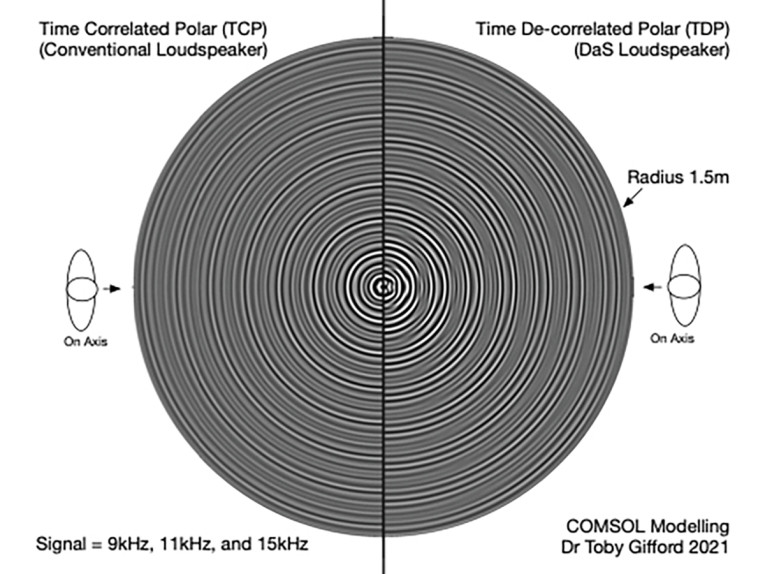
When a harmonically driven (constant signal or steady state response) audio signal occurs, acoustic energy is released at different “time/phases” in the polar plane. Each frequency has its own unique spatial shape.
As expected, in the left-hand image (TCP) of Figure 2, the sound field is exactly the same in each polar direction. In the right-hand image (DaS/TDP) of Figure 2, you can see both the bent elliptical nature of the three different frequencies, and most important, how each polar direction is completely different (decorrelated) in the sound field. It is physically impossible, even in a perfectly flat glass-walled listening room, for the reflected room energy from a DaS loudspeaker to be the same as the direct sound one would hear standing at one particular polar angle. Yes, DaS can turn a glass-clad room into an ideal acoustic environment, through the loudspeaker itself.
One huge benefit of the bending of time (TDP) is that echo-locating the source of the sound (the loudspeaker) becomes near impossible. “Out of box” sound becomes dominant, wherein the sound appears to have completely detached itself from the loudspeaker source.
Step Response Behavior (AuReality)
The ability to “create an ideal listening room environment” through DaS is, in itself, very exciting. But there is also the transformational ability of the technology, to make the step response driven sound field in the listening room to rotate, thus creating dominant intra-aural intensity differences (IID) cues for the listener. This causes DaS AuReality loudspeakers to have a presence that takes on an “amazing air” of reality!
A long time ago in my career, I worked on Guitar MIDI controllers. This work informed me about the time/frequency nature of musical information. I call this the “ergonomics” in room acoustics. You can think of this as the interaction between humans and acoustic spaces. These ergonomic observations—such as the 5ms threshold for a perceivable delay between a musician’s action and hearing a response — have influenced the design of DaS AuReality.
The original Yamaha DX7 synthesizer, allegedly the first equipped with MIDI, introduced to the design at the last minute before release (1983), suffered from an alleged internal MIDI latency around 10ms. This made it hard for virtuoso musicians to push the instrument via MIDI in certain performance situations.
The most applicable knowledge I learned from doing that guitar synth work, was that of the ergonomics of the musical performance itself. Things such as the number of cycles of a frequency that you would find, for example, in a short bass note. A very staccato bass note may have only 5 cycles of the fundamental between turning on and turning off. The fastest guitar player we could find back then could not even play 20 notes per second. Twenty notes per second also happens to be the equivalent to a 50ms interval between notes, the threshold in auditorium acoustics at which an early arrival time for the first correlated reflection starts to be heard as individual echoes (or individual notes)!
A short bass note, with a duration of 50ms, still has plenty of opportunity to set up a series of correlated specular reflections in a listening room. Fifty milliseconds is 18 meters when travelling at the speed of sound. That is quite a few laps of a small room. This series of correlated specular reflections is true for both the recording environment, caught in the audio, and in the reproduction environment, exhibited during playback. This also raises the additional question, is there a way to make these recorded reflection events in the audio become dominant in the listening room acoustic? The answer is yes, through AuReality.
Part of the mechanism for setting up the DaS decorrelation sound field is the use of a prime number of drivers. This would normally cause issues with the transient nature of sounds, the “attack”! Our engineers have developed a way to make the acoustical response to sudden changes in the audio signal (step response) to act like real acoustic reflections, in the now diffused listening room. It does this by harnessing the behavior of wave packet transients.
When a sudden energy is applied to the driver array, the energy between the individual elements of the array creates a wave packet transient output. This wave packet transient has very unique properties that are useful to psychoacoustic perception. The acoustical output is symmetrical about the y-axis, thus it is acausal (and therefore linear phase)! The shape of the wave packet does not change over distance (it is not dispersive). Consequently, DaS loudspeakers do not suffer from tonal distortional over distance. The sound simply gets softer, until you can no longer hear it, but remains a totally intelligible unit at that point.
This wave packet transient creates very strong interaural intensity differences (IID), all be it for a very short period of time (a sonic atom: Denis Gabor [2]). To the listener, suddenly the spatial cues caught in the audio recording start to stand out as a strong acoustical phenomena in the diffused listening room. We, the listeners, are picking up the benefits of DaS (decorrelation). We are also clearly picking up the audio spatial cues, through listener IDDs, in the recording’s “early reflection patterns — space.”
This acoustical stack of benefits, DaS AuReality (wave packet rotational sound fields), and each harmonically driven frequency having a slightly different spatial shape/presence, gives the sound field an uncanny resemblance to those of real life sound fields.
Application in the Audio Spectrum
To understand market segment applications, it is worth discussing how each technology embodiment might be realized. Smartphones are an exciting market segment. The application of Das AuReality may be realized using an array of the USound micro piezo drivers. Or, to that matter, any MEMS or microspeaker drivers [3].
Hi-fi tweeters are healthy, low-hanging fruit for immediate DaS AuReality product realization! Through the advent of the micro speaker drivers for laptop and pill speaker use, there are now a proliferation of small, high quality, low cost, dynamic loudspeaker drivers available.
Table 1 shows how the diffusion bandwidth ratio and the required amp channels change with DaS array size. The practical challenge is to maximize the DaS effect without creating too much complexity and cost in the solution. The choice of seven drivers presents as a very good, practical option. It has a bandwidth ratio of 13. With seven drivers, we can build a DaS AuReality solution with a diffusion bandwidth from 1kHz to 13kHz. This seven-driver solution requires four channels of amplification.
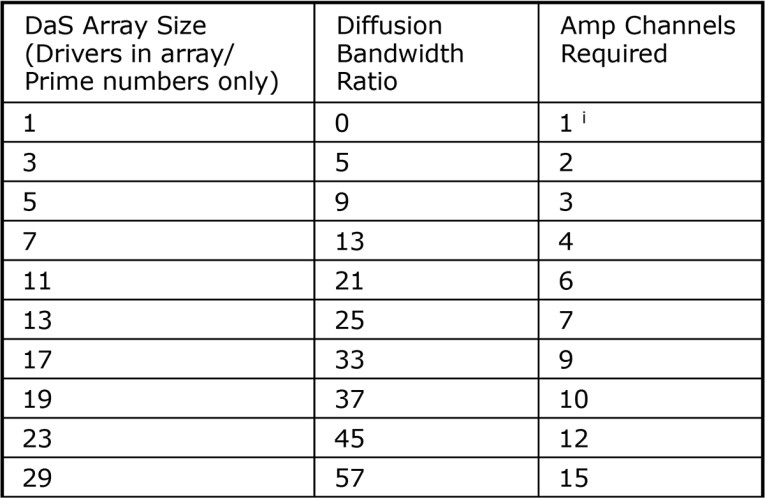
i Equivalent to a conventional speaker with one driver
The digital DaS AuReality tweeter shown in Photo 1 uses an array of seven off, 34mm x 11mm drivers. The four channels of amplification are currently achieved through using 2× Texas Instrument TAS5825M chips. These chips are sufficient for holding our proprietary DSP, as well as basic crossover and EQ settings. While each TAS5825M is capable of producing 2×50W (4Ω) we effectively have 8Ω drivers (2× 4Ω 3W RMS in series), and only need 12W RMS per channels to drive 6W RMS of driver capacity. The tweeter in Photo 1 is the equivalent of a 21W RMS device.
In practice, the tweeter shown in Photo 1 works from 1,500Hz, and is capable of more than “holding its own” in a high-end bookshelf speaker scenario. It is suitable in multiple applications, from soundbars to Hi-Fi equipment, and studio monitors.
We also see an application where multiple rows (columns) of these drivers are aggregated to very high-power levels, for concert sound (PA) applications. Photo 3 shows an array of 16mm × 9mm 0.5W RMS drivers, suitable for pill and or small speakers. This requires three channels at 2W RMS amplification, with the array being five driver elements.

We have thus far concentrated mainly on applying DaS to the higher frequencies where specular reflections have the most deleterious consequences on sound perception. We have also applied DaS to a low frequency band, 90Hz to 450Hz (Array size = 3 in Table 1) and achieved the same “realistic” sound and presence. In this case, the drivers need to be no wider that the half wavelength of 450Hz, 38cm.
To complete the scenario of applications, let’s look in more detail at concert PA sound (Figure 3). The Texas Instrument TAS5825M chips can be used in bridged mode to achieve 100W RMS into 4Ω. Using 25W RMS drivers per element (perhaps a column of eight high 34mm × 11mm 3W RMS drivers), one could build a concert PA array with 29 driver elements per row, requiring 15 channels of amplification (8× TAS5825M chips), totaling 1,500W RMS. The solution would be 29 drivers wide, and 8 rows high, and would fit inside a 400mm2 enclosure. As it is PCB-based, this concert PA driver is not too complicated, not too expensive, and uses contemporary available complete-off-the-shelf (COTS) componentry. It is like building with Lego blocks!
Additional beneficiaries of the DaS AuReality technology, may well be the touring musicians who, instead of regularly performing in an acoustically challenging venue, can now completely remove that “venue acoustics influence” from the performance sound. Likewise, wouldn’t we all want to start hearing intelligible announcements at airports and train stations! In addition, for the hearing impaired, due to the removal of specular reflections, we have found that using DaS enables them to listen to the TV, even at moderate levels, despite hearing loss or needing to wear hearing aids.
Conclusion
The ability to easily and effectively eliminate the listening room acoustical specular reflections, creates an “uncannily real listening environment,” where the performer’s every nuance becomes audible. We believe this is truly “Sound beyond Space and Time.” We also predict that for serious music lovers and audiophiles, once they have heard a “DaS AuReality enabled” loudspeaker, it will become their “must-have device” in their sound system! For information regarding technology licensing or partnering enquires, contact Olavs Ritenis, VP Global Business Development, Vastigo, Ltd. at +65 9339 4536 (Singapore) or contact us through this email. VC
References
[1] Corsini Acoustic Solutions,
www.corsini.com.au/product-page/myron-e-diffuser
[2] “Dennis Gabor,” Wikipedia,
https://en.wikipedia.org/wiki/Dennis_Gabor
[3] M. Klasco and N. Wong, “MEMS Speaker Vendor Directory 2021,” Voice Coil, May 2021, Volume 34, Issue 7, pp. 13–17.
This article was originally published in Voice Coil, September 2021.