


As Bluetooth protocols with enhanced sound quality along with stereo brought us wireless headphones paired to smartphones, which added fuel to the fire, we are reaching full ignition with voice assistance emerging in everything from smart speakers to soundbars, smart wall outlets, and now smart TVs.
Voice processing has been with us since the start of Bell Labs, which was initially a telephony research department at AT&T’s Western Electric set up in 1907. While Bell Labs has undertaken a wide range of research, voice was its primary focus from encryption vocoders to compressor/limiters and uplink and down link noise filtering to transducer refinements.
The radio broadcast industry has always been obsessed with extracting the maximum range from their transmitters — as advertising rates are calculated by the listener coverage area. In the 1950s, the CBS Volumax was the first effective broadcast automatic gain control (AGC) but its original purpose was to eliminate the signal level watchman — a technician whose only job was to prevent transmitter over-modulation. This overload would blow up the expensive transmitter tubes not to mention over-modulation would incur the wrath of the Federal Communications Commission (FCC).
It did not take long for radio stations to also realize the dynamically compressed signal traveled to the fringe reception areas more clearly. Decades later, it was multi-band limiters such Orban’s Optimod and the Aphex Compeller that ruled the broadcast waves. In the 1970s, the back rooms of intelligence agencies were using sophisticated forensic voice processors such as those from Rockwell (now Rockwell Collins) to extract intelligible speech from noisy signals.
Today, you don’t have to look behind secret doors to find some of the most sophisticated voice processing — it is in your pocket—in your smartphone. More than 1.6 billion cell phones are sold each year and that kind of number is hard to beat in the consumer electronics industry.
Smartphones are big on signal processing, voice for telephony communications, and also for music playback, gaming, and movies. Voice processing is the unsung hero in mobile audio devices—significantly enhancing voice call quality, intelligibility, and speech recognition (command) accuracy. Voice processing enables natural full-duplex communication in speakerphones, suppressing echo and acoustic feedback, and beamforming the mics for clear speech conversations in noisy places.
The vendors of these voice processing technologies operate in a fiercely competitive market, which drives continuous product design improvements. Further innovative R&D efforts will no doubt lead to better, faster, less expensive solutions that will benefit mobile device users in years to come.
Some of the processing takes place in the voice co-processor/codec (e.g., from Qualcomm and Cirrus Logic), but the processing smarts are distributed around a bit. Some processing, such as active noise cancelation (ANC), is starting to appear in the USB-C audio signal chain. And, most smartphones drive the receiver (earpiece) and speaker (speakerphone) with a smart amp, which monitors excursion and voice coil heat and limits operation to the safe operating area (SOA) of the speaker system.
The bottom line is smart amps enable manufacturers to get more sound out of tiny speakers crammed into shrink-wrapped enclosures without distortion, death, and destruction. Most of the leading semiconductor amp chip vendors such as NXP, Qualcomm, Texas Instruments (TI), and Maxim now offer smart amps.
Early Smartphones
Early mobile phone voice signal processing research was conducted by Motorola, Nokia, Ericsson, and the other pioneering mobile phone companies. Apple’s Newton digital personal assistant, soon followed by Apple’s development of iTunes (with iTunes initial launch in a Motorola mobile phone in 2004), and all this coalesced with the iPhone 2G, which debuted in 2007.
As smartphone computing power continued to ramp up, so did the voice processing in the audio hub/co-processor. Third-party algorithm specialists emerged, with many now absorbed by bigger fish. SoftMax (now Qualcomm’s Fluence), Acoustic-Tech (now Cirrus Logic’s SoundClear), Audience (merged into Knowles Intelligent Microphones), Convergent (now merged in Synaptics), among others, all fought each other for smartphone, tablet, and laptop design wins. A more recent entry (with some design wins in Samsung phones) is DSP Group’s HDClear. Today, even the least sophisticated phone has processing power beyond the dreams of anyone just a few decades ago.
Voice Challenges
Let’s state the obvious, while there are endless app and personal assistant functions, a mobile phone, at its core purpose, is voice communication and as such, sound clarity is the highest priority. The goal is to provide clearly intelligible speech in noisy environments. With the uplink (what you say) and the downlink (what the receiving party hears), users expect to communicate without intrusive noise. Every day users are taking calls while walking down a busy street in NYC, driving in a car with the window open and the radio blaring, at a windy beach, or in the din of a crowded restaurant). All these examples are challenging environments for even the most sophisticated state-of-the-art signal processing algorithms.
Aside from voice processing for the obsequious smartphone, we have Bluetooth earphones and headphones. In 2017, the dollar value of Bluetooth earphones and headphones exceeded wired versions. There are two types of DSP cores embedded in the chipset or system-on-a-chip (SoC). For cost-effective implementations the algorithms options available are in the read-only memory (ROM) embedded into the Bluetooth. The product development team at the headphone brand will pay to enable the features they want.
The more sophisticated and flexible path is to select the flash memory version of the Bluetooth IC, where special algorithm features can be selected and programed into the flash memory to run on the on-board DSP Bluetooth processor section of the Bluetooth IC.
Smart codecs combine the D/A codec with a DSP core and this approach is used for most digital wired ANC headphones, but more recently it is also used in the USB-C signal chain. Headphones that have a direct connection to the USB-C jack have yet to get traction with the brands.
Another approach to signal processing is a dedicated chip in the form of an application specific integrated circuit (ASIC), which can be interfaced with most of the preceding circuits. Moving out of consumer audio electronics, the same types of voice signal processing can be found in desk speakerphones and conference phones and so forth.

Voice Co-Processors
A co-processor’s function is to assist the primary processor with specific tasks — increasing performance or freeing up processing power that can be used for something else. In desktop and laptop computers, dedicated graphics chips or graphics processing units (GPUs) co-processors take the heavy demands of visual processing away from the central processing unit (CPU).
Also, sound cards can be considered a class of audio co-processors that boast higher audio quality codecs, multichannel audio playback, and real-time audio DSP effects. Now, most smartphones use dedicated integrated circuit (IC) voice co-processors that are a type of ASIC. In the most sophisticated adaptive processors, intelligent speech tracking and adaptive processing analyze ongoing speech patterns and environmental conditions in real time.
The result is a self-adjusting signal-dependent algorithm that emphasizes voice quality — whether in a quiet room or the noisiest vehicle, using techniques such as automatic level control and automatic volume control.
Noise suppression processing contends with crowd noise, audience babble, and similarly variable and unpredictable complex ambient noise that can significantly degrade speech intelligibility. Only the most sophisticated voice processors can effectively separate and filter this type of random noise from the speech signal. Mobile audio products tackle wind noise suppression through acoustics and signal processing. Yet signal processing is not a complete solution (e.g., when the mic is saturated when overloaded by the wind) and the signal output from the mic is distorted, then no amount of signal processing will be able to extract what was not cleanly captured.
The first line of defense from wind noise is acoustic filtering and is achieved through the use of mesh or non-woven wind screens, which is the same materials used in professional stage microphones. These materials are designed to be acoustically transparent while blocking the wind’s force before it can overdrive the microphone’s diaphragm. Once the microphone diaphragm is hit by too much wind pressure — "too much" is the acoustic overload point (AOP) — then, the signal processing cannot do much to help. Many filter membrane materials also have high (IP) values, which means they act as barriers to prevent dust and moisture from entering the microphone.
Once past the wind screen’s acoustic filtering, any remaining noise component of the wind turbulence can be attenuated through signal processing. Wind is not a constant noise. Between the wind’s changing speed and direction, the user’s unpredictable path, and the device’s aerodynamics, we receive “nonstationary” noise. This means the noise’s direction, amplitude, envelope shape, and duration may all vary in a random fashion. Contrast this with stationary noise (e.g., a motor at constant speed and load when the user is not moving relative to the noise source). This situational noise is more easily suppressed with less computationally intensive signal processing.
Another type of noise that adaptive noise filtering must contend with comes from heating ventilation air conditioning (HVAC) systems. While air ventilation noise may not be that noticeable to those using a conference phone in a meeting room, for those on the receiving side of the call this type of noise can make the conversation fatiguing and unpleasant. Our hearing uses both ears to help us “tune out” ambient noise, but when the noise and the voice communication emanate from a single speaker source, our natural psychoacoustic processing does not work.
In the case of a party or similar environment where there are many simultaneous conversations (crowd babble), we experience the “cocktail party” effect. This lets us use our binaural hearing to zoom in on a single conversation that is not necessarily louder than the next. Dolby Labs has introduced a conference phone that actually enables up to three people to talk from the source room and (assuming both sides have this system) be reproduced through separate loudspeakers spaced in a circle, which reproduces the “cocktail party” effect.
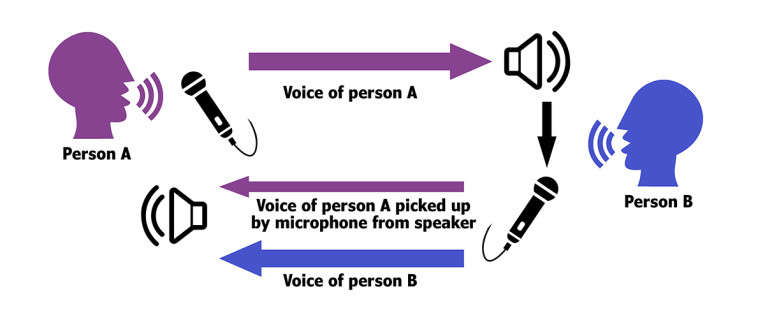
Acoustic echo cancelers (AEC) are signal processing methods used to improve voice quality either by preventing echo from being created or removing it after it is already present. Consider a full-duplex speakerphone — when you talk, your voice will be reproduced at the far location through a speaker. If the microphone gain at the far location is too high (above unity gain), then your voice from the loudspeaker will be picked up by the microphone and sent back to you, resulting in an echo.
There is always some degree of latency in voice communications systems, so the echo is further delayed, which can make conversation impossible. When conditions are right (wrong, actually!), the microphone will pick up your echoed voice and send it back to the other location and the feedback loop begins.
Echo suppressors work by detecting a voice signal traveling in one direction on a circuit, and then inserting loss in the other direction. Usually, the echo suppressor at the circuit’s far-end adds this loss when it detects a voice coming from the circuit’s near-end. This added loss prevents the speaker from hearing his own voice. Echo cancellation involves first recognizing the originally transmitted signal that re-appears, with some delay, in the transmitted or received signal. Once the echo is recognized, it can be removed by subtracting it from the transmitted or received signal.
This technique is digitally implemented using an algorithm running on digital signal processor. AEC enables natural full-duplex conversations — two singers at distant locations can sing a duet without interference created by the send/receive signal paths.
The Near Future is Far Field
After decades of voice recognition development, with voice assistants (e.g., Apple’s Siri and Microsoft’s Cortana) introduced on smartphones and PCs, Voice Command Appliances (e.g., Google Home, Amazon Echo, and similar devices) have energized the smart home market. Finally, the accuracy of near-field voice assistance is robust. Near-field use cases include headphones even without a boom, talking to a laptop or smartphone, smart speakers that are nearby, and other use cases where the mic(s) are less than 6’ away from the talker.
Voice recognition processing is still a challenge when your voice commands have to compete with ambient noise (e.g., the TV or radio) but also when more than 7’ or 8' from the source accuracy results start getting marginal. So, at the moment, sitting on the couch watching TV with the sound blasting, and changing channels or the volume through far-field voice command, remains elusive.
And no exploration of voice assistants and voice command is complete without touching on Sensory wake words used to trigger the service. Sensory’s voice technologies are omnipresent in consumer electronics applications including mobile phones, automotive, wearables, toys, IoT, and home electronics. Sensory’s TrulyHandsfree voice control is the standard for smartphone’ ultra-low power “always listening” voice control — embedded in more than a billion consumer products.
Sensory has developed a suite of voice models for Alexa that are part of Sensory’s TrulyHandsfree speech recognition engine. Now offering multiple phrase technology that recognizes, analyzes, and responds to dozens of key words, it consistently recognizes phrases even when embedded in sentences and surrounded by (modest levels of) noise. Sensory technology is now part of Qualcomm’s FluentSoft SDK and for Android environments with other platforms.
Integrated TrulyHandsfree enables products to wake up and respond when the trigger word is called, so no button pressing, or manual manipulation is needed. This very low-power technology is designed to prevent false triggers during normal room noise and conversations. One promising development to improve the implementation of voice recognition is the Whisper voice extraction processing that was originally developed by Kopin for communication in the extremely high noise environments of the F35 fighter cockpit helmets.
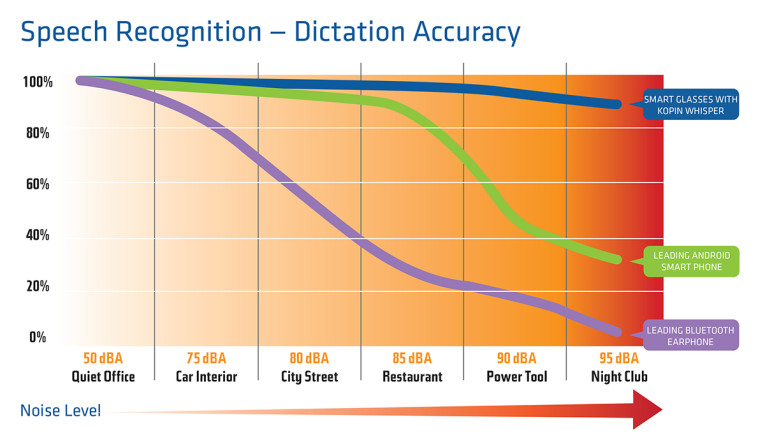
This pre-processor (roughly) doubles the accuracy of automatic speech recognition while improving far-field voice quality in smartphones, wearables, and voice command appliances. The algorithm can also run on some of the Bluetooth chips that accommodate flash memory. I had the opportunity to check this out myself and was impressed. I expect to see this embedded in a lot of products.
All this technology is the tip of the iceberg in voice processing and the tipping point for the use of voice interfaces in the smart home. For decades, there has been a struggle to make voice command and smart homes viable in real life. At the 2018 CEDIA show, voice assistance was embedded in most upcoming products being introduced at the show. The technology now has a toehold and it is only up from here. aX
This article was originally published in audioXpress, December 2018



