



Extract Clean Sound in Noisy Environments
Voice Coil continues its look at microphones with this exciting feature on optic sound pickup technology. VocalZoom, founded in 2010, has developed a unique laser sensor which, when used as a microphone, can differentiate a speaker’s voice from extraneous background noise. The VocalZoom sensor can be simultaneously used as a biometric sensor and a 3-D imaging sensor.
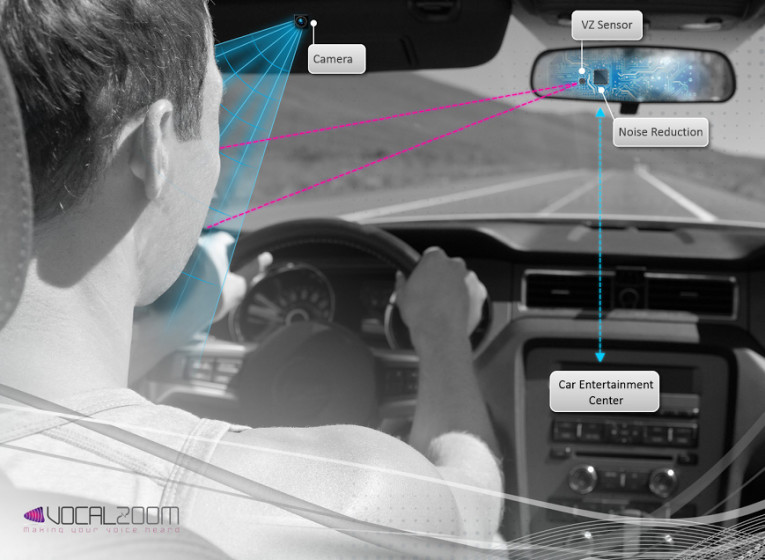
The technology creates a virtual cube, sensing sound from within the cube. The first generation laser microphone is a 3 mm × 3 mm module aimed for short distances, up to 10 cm, which will be available during the first quarter of 2016. The second generation, which will target 1 m distances and be focused on automotive applications, is expected to be released in 2017.
The technology is ingenious and combines a conventional audio microphone capsule in conjunction with the VocalZoom laser microphone. The laser microphone “looks” at the vibrations from the user’s facial skin (e.g., mouth, lips, cheeks, or throat) as a reference to determine which of the sounds the conventional microphone picks up actually emanates from the user.
The popular Jawbone Bluetooth device has a similar concept, using a contact microphone pickup pressed against the user’s cheek. Jawbone’s term for this sound source separation process is the “voice activity detector.” Unlike the Jawbone, the VocalZoom sensor is optical. By not being in physical contact with the user’s cheek, the upper voice range is not damped out. With this relatively wideband speech information, digital signal processing can be used to clean up the audio and eliminate most extraneous noise. If the person wearing the VocalZoom pickup is not speaking, the conventional microphone picks up the sound, but the algorithm in the processor does not pass on the signal, as it is extraneous.
The noise suppression’s effectiveness is an improvement from microphone arrays and it enables precise speaker isolation. These aspects are key elements that will enable mass-usage of voice-driven applications (voice recognition) for devices such as communication radios, infotainment autosound systems, and smartphones. The technology is built into a miniature module — similar in size to a cellphone camera module — available to OEMs. The company estimates the module could be sold for as little as a couple of dollars for a minimal configuration.
In characterizing a microphone’s operation, there are two parameters: the transducer “mechanism” and the pickup pattern. Most consumer application microphone capsules are electret condenser microphones (ECM) or microelectromechanical systems (MEMS) microphones. But for professional users, dynamic pure external bias condensers and ribbons have their place. The pickup pattern is the microphone’s polar response, which can be omni-directional or uni-directional. For directional microphones, the most common pattern is cardioid, but specialty requirements can be hyper cardioid (tight) or figure 8 (dipole). MEMS microphones have the limitation of only being available as omni-directional. To obtain pattern control, MEMS microphones are used in arrays.
Directional microphones and microphone arrays differentiate between the desired sound source and suppression of any nearby noise (e.g., non-target talkers) is only marginally adequate in most applications. Even more unacceptable is the poor accuracy of speech command (speech recognition) found with conventional microphones. We have all experienced the silly or helpless responses from voice commands to Siri, Google Voice, and other voice-recognition apps (e.g., your car infotainment systems).

Applications
An amazing initial application for the compact IC footprint of laser microphones, is usage in autosound infotainment systems. By infotainment systems, we mean everything ranging from clean speech communications for the car’s hands free system to robust stable voice command of the vehicle infotainment system, even with the radio on or the windows open (see Photo 1).
In the automotive industry, it is expected that more than half of new vehicles will integrate speech recognition, as manufacturers seek safer and less distracting ways for drivers to interact with navigation, audio, and Bluetooth systems. The new era of connected cars and autonomous cars imply more and more functionalities in the car, and the only way to void distraction and have intuitive control is with voice commands. However, many people using in car and other speech recognition technologies remain dissatisfied with the reliability and accuracy.
Optical Transducers
But, let’s look back before we look ahead. Optical transducers are not new, old guys like me remember from the late 1960s, Kenwood’s Supreme 20 optical phonograph cartridge, which used a beam of light modulated by a stylus motion with a pair of screens mounted in a “V” formation. On the screens were a pair of photo-electric cells. As the stylus tracked the groove, the cantilever moved the screen and caused variations in the pattern of light falling onto the cells. About 25 years later (the 1980s), the Final Optical Turntable was far more advanced, using a laser pickup to read the modulations of the record groove.
Non-contact sensors acquire speech signals by detecting the vibration of the vocal track and the articulars (i.e., the lips, the teeth, and the tongue) and include optical sensors, such as infrared rays, light waves, and lasers. Optical sensors enable acquisition of speech/acoustic signals with a high-degree of precision. Until VocalZoom’s laser microphone, these optical transducers were expensive, provided poor in performance, had complex interfaces, and were limited to industrial, military (surveillance), and medical applications (see Photo 2).
Around 2009, Sennheiser commercialized the MO 2000, its optical microphone, which used light to measure movement of a conventional microphone membrane (and not the target vibrations as does the VocalZoom laser microphone). This is an industrial transducer that processes acoustic signals on the basis of variations in light intensity. In the medical field, this optical microphone is used in magnetic resonance imaging (MRI) for communication with the patient during MRI scans.
Other optical microphones are used for long-distance sound pickup for surveillance, with a laser beam to detect sound vibrations in a distant object. This technology can be used to eavesdrop with minimal chance of exposure.
The signal source is typically inside a room. The signal source can be anything that vibrates (e.g., a picture on a wall) in response to the pressure waves created by noises in the room. The laser beam is directed into the room through a window, reflects off the object, and returns to a receiver that converts the beam to an audio signal. The beam may also be bounced off the window itself.
The minute differences in the distance traveled by the light as it reflects from the vibrating object are interferometrically detected. The interferometer converts the variations to intensity variations, and electronics are used to convert these variations to signals that can be converted back to sound.
These technologies suffer from high levels of noise due to changes in the air medium caused by even slight wind or temperature variations. Also these technologies are based on conventional interferometers, which are expensive and overly sensitive. These optical microphones measure vibration from surfaces in the speaker’s vicinity, which vibrate due to the speech as well as noise.
Vibrations of human skin, on the other hand, are only caused by speech, and provide super directional pickup. Optical microphones, such as the one from VocalZoom, measure the skin vibrations and can listen to the speaker’s voice, separated from the noise.
When optical microphones are fully implemented in MEMS microphones, they can be integrated into next generation smartphones. The microphone located on the bottom edge of the smartphone, does not touch the face, yet it can be aimed at the cheek to pick up speech vibrations.
Conventional airborne sound pickup microphones plus laser microphones can also be used in a smartphone to pick up skin vibration for speech pickup. The smartphone would be conventionally held, and an optical microphone would be positioned adjacent to the typical MEMS microphone toward the bottom of the phone. Not only would the talker’s speech be picked up by the optical microphone — without crowd din, street noise, or HVAC (air conditioner) noise — but structural leakage between the microphone and the speakers could be processed out, due to the reference signal from the optic voice activity sensor (the VocalZoom microphone). This would enhance the stability of the acoustic echo cancelation algorithm in full-duplex operation (see Figure 1).
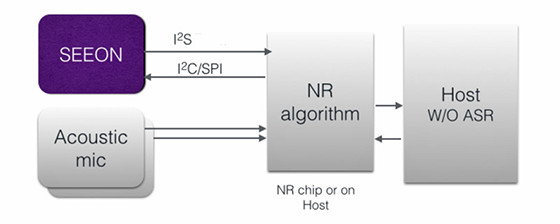
Optical Microphones
Let’s consider how an optical microphone is such a powerful solution for clean audio pickup in noisy environments compared to microphone arrays (although both approaches can be used for higher performance). The optical pickup is the only remote-pickup technology that senses the cheek as a membrane for skin vibrations.
This provides an independent and reliable reference audio signal, in any environment. Unlike conventional microphones, which only pick up airborne sound energy, the optical microphone picks up skin vibration speech energy by reflecting light from the cheek of the talker to the optical microphone’s sensor. The wave vibration power in air is much weaker than in body tissues. Therefore, the voice volume in the same tissue position is higher than the background noise. In contrast, skin vibration microphones pick up the speaker’s voice though soft tissue media, not air media. Skin/soft tissues vibrate only because of sound bouncing in the inner body vocal cords. Sound waves from outside the body create minimal vibrations inside the body soft tissues (0.001 less effect than from the inner voice). Soft tissues also provide more accurate transconduction of sound than bones and preserve higher frequencies.
Jawbone is currently one of the few consumer products in mass production that uses bone conduction voice activity pickup (in conjunction with a conventional ECM). Signal processing compares the microphone pickup of airborne speech and the audio signal to the cheekbone speech pickup. Airborne signals that do not correlate with cheek bone production are not passed along.
Contact pickups (e.g., those used in the Jawbone over-the-ear Bluetooth headsets) press against the cheek membrane. This pressure against the skin dampens and rolls off the top-end of the speech signal pickup. These contact-type sensors make some users uncomfortable, can cause allergies, and restrict activity — although this is dependent on the sensor’s location and its interface with the user’s skin. Another aspect is the “cyborg” appearance since these devices are worn on the head.

Getting Started
For product development, VocalZoom offers demonstration kits that can be used for evaluation and application development both for short-range applications and for far-field applications. A first generation compact footprint module, available in first quarter of 2016, is straight beam for distance up to 10 cm. VocalZoom’s roadmap for a second-generation device, available late 2017 is for distance of up to a 1 m and has a multi-beam design (e.g., it has a field of view of 30°).
The sensor is also being tested for additional applications. The sensor’s bandwidth now measures up to 1 kHz from facial vibrations. The next generation should reach 2 kHz signal (see Photo 3). VocalZoom also plans to improve the device’s voice biometrics that—based on the optical raw data without the need for acoustic microphone — will further decrease footprint.
The company is also looking at the microphone’s biological biometrics, based on skin elasticity extracted from the skin vibrations measurements. Combined with voice biometrics, this enables Multi-Factor Authentication, using a single sensor.
For 3-D imaging, the multi-beam sensor would enable each beam to accurately measure distance. Therefore, the sensor can provide a 3-D image of the target. Today, laboratory prototypes demonstrate this capability with a scanning laser beam using a MEMS mirror.
Another application involves advanced integration with speech recognition. VocalZoom is developing a new approach to improve of Automatic Speech Recognition (ASR) not through the usual approach of noise reduction, but rather through a new speech recognition design using the optical raw data.
All this is quite ambitious and will require both engineering passion and staying power. VocalZoom investors include 3M Corp., Motorola Solutions, OurCrowd, Radiant, and FueTrek Co., so there is enough momentum behind this development to reach mainstream commercialization.
For more information, contact Tal Bakish, VocalZoom Systems CEO by email or visit, www.vocalzoom.com
This article was originally published in Voice Coil, December 2015.



