


Sound System Debate
Whether the sound system’s goal is “accurate” reproduction or simply “pleasing” reproduction is often discussed. Often, accuracy of reproduction is assumed to be the goal. In saying this, one must recognize the impossibility (futility?) of recreating, in one acoustic space, a sound field generated in another acoustic space.
Yet, much of this difficulty stems from differences in directional cues and reverberation. Directional cues are primarily a matter of loudspeaker positioning, room geometry, and acoustics. Reverberation in a listening room seems to be largely factored out of perception by the human ear/brain mechanism. We become accustomed to the sound of the room we’re in. Thus, we can theoretically come pretty close to recreating the same perceptual experience in our listening room as was experienced in the original venue. The focus in this series of articles is the presence, or absence, of different amplifiers’s differences in sounds.
Given the goal defined in the previous paragraph, I have dived headlong into the “measurement versus perception” debate. Numerous sound-system attribution studies have been made in an effort to correlate physical measurements with listener perceptions in the evaluation of sound systems. Albert Einstein said everything should be made as simple as possible — but no simpler. If we hear differences in the sound of different amplifiers, we try to explain why the differences exist. At any point in our understanding, we may fall prey to the assumption that all perceived elements correlate with the presently popular set of measurable characteristics.
The result of this unfortunate tendency has been to alienate a certain portion of audiophiles from the scientific side of the field, to the point that they may suggest perception is everything and measurements are meaningless. At the other extreme are those claiming our present level of understanding is sufficient to completely characterize perceptual response to a sound system in terms of measurements alone. While this is certainly the goal, it has not yet been realized.
So, neither of the extreme views helps us progress in the art and science of sound reinforcement and reproduction.
Outside Influences
Recognizing that listeners’ sound equipment opinions do not always correlate with measured performance ratings, many researchers have studied the subjective evaluation process of components and systems. Their intent has been to maximize the amount of equipment-related information that can be extracted from such evaluations while minimizing extraneous information input. Examples of extraneous input are numerous. Listeners evaluating speaker systems respond more favorably to equipment with known brand names, even if the equipment they are praising was manufactured by company A, and the nameplate from the well-known manufacturer company B was substituted for the original.
Listeners have been shown to prefer speaker A over speaker B when the sound level from speaker A was only a few tenths of a decibel higher than that of speaker B (due to differences in electrical drive levels). They switched their preference to speaker B when its level was raised above that of speaker A. The cabinet appearance also affects listeners’ sound quality perception. A speaker’s room location, both in relation to the listener and in relation to the room boundaries, affects preferences. The list goes on, and some of it applies to amplifiers as well as speakers.
The multitude of extraneous information that can intrude into a subjective evaluation is such that some professionals have characterized subjective testing as useless. And yet, we live in subjectivity. A perception that is true for the perceiver may not be true for other persons, meaning a subjectively true perception is not necessarily objectively true. The problem is not with subjectivity, but with deriving relevant and repeatable information from subjective tests while rejecting the irrelevant and non-repeatable. When this is accomplished, the subjective test results yield useful buying recommendations for listeners and can provide valuable input for product design improvements.
Two excellent examples come from the history of power amplifier design. In the early days of solid-state amplification, transistor amplifiers suffered a bad reputation due to what was described as a “harsh sound.” After design theory advanced to include techniques for applying the correct bias current throughout the full operating temperature range, crossover distortion of solid-state amplifiers was reduced to low levels, and most of these complaints subsided.
But, since distortion was usually measured at full output and crossover distortion is negligible except at low output levels, the objectionable levels of distortion were not noticed until subjective complaints alerted us to them. A similar situation obtained in the 1970s, beginning with Matti Otala’s work on transient intermodulation distortion (TIM). This distortion is difficult to measure, as it only occurs during transients, and then only if the amplifier’s slew rate is so low the negative feedback signal is unacceptably delayed in its action. When this occurs, the negative feedback’s distortion-reducing action does not occur, and momentary high levels of distortion occur in the signal. TIM’s effects are clearly audible to careful listeners, but until the cause was identified, that audible perception could not lead to the design improvements that eliminated TIM.
AES Guidelines
In 1996, the Audio Engineering Society (AES) published “AES20-1996: AES Recommended Practice for Professional Audio—Subjective Evaluation of Loudspeakers.” It was written after years of collaborative work by some of the finest minds in the field. This standard (revised in 2007) provides valuable guidelines that should be observed in any effort to obtain useful subjective information on any piece of sound-system equipment.
It is based upon careful, thorough science, and while it makes no claim to being the last word on the topic, it well summarizes a helpful approach to this emotion-laden area. AES20 is focused on speaker evaluation, but many of its insights apply to any sound equipment’s subjective evaluation. Guidelines included in the standard can be grouped into four areas: room requirements, listening arrangement, program material, and test procedures. I will examine the last two areas, as they are most appropriate to tube amp sound.
Program Material
Program material should be chosen with several specific goals in mind. First, it should be material for which almost anyone can recognize whatever aural defects the test system may introduce. Foremost among such program material is the human speaking and singing voice. Acoustical instruments are also good. Electronic instruments have no native sound: their sound varies depending on the instrument’s setup and amplification. Therefore, no matter how much a particular listener may personally like any given recorded performance or group, electronic instruments should be used only for specific purposes during listening tests, (e.g., width of frequency response and ability to handle power).
They are not generally suitable for evaluating frequency-response flatness (“accuracy”) or subtle distortion levels. Second, the material should provide extremes of both frequency and dynamic content. Since music sounds most natural when heard at concert levels normal for that style of music, electronic music can be profitably used to test a system’s ability to produce high levels. It is also important to remember sound systems can easily produce damaging sound levels, so high playback levels should be limited to safe time durations. Many references are available to help determine these levels.

Occupational Safety and Health Administration (OSHA) guidelines set a maximum limit of SPL and duration, in that a certain percentage of the population will experience permanent hearing damage even when adhering to OSHA guidelines. Table 1 shows the OSHA noise exposure guidelines. It is a good idea to limit exposure to 5 dBA below the levels.
Third, percussive instruments (e.g., piano and steel drums) can provide useful tests of a component’s transient performance. And finally, imaging tests require program material that contains well-defined sonic images. This is not always true of otherwise good recordings. (Imaging concerns apply mainly to speakers. It is difficult to imagine any way in which an amplifier can affect imaging.)
AES20 contains the following recommendations concerning program material, plus others specifically applicable to testing of equipment other than amplifiers:
• The material should include one anechoic recording of the male speaking voice, made using an omnidirectional microphone.
• The material should contain solo male and female singers.
• The above material by itself should contain sufficient breadth of frequency, transients, and dynamic range to provide a good system test.
• Test signals (e.g., pink noise and sine sweeps) should be used first to check for defects (e.g., speaker buzzes, out-of-phase connections, etc.).
• Music featuring electronic instruments should be used last to test the system’s dynamic capabilities. (Loud levels may induce fatigue or even a temporary hearing threshold shift in listeners, rendering them less suitable for further testing until the ears have rested.)
Test Procedures
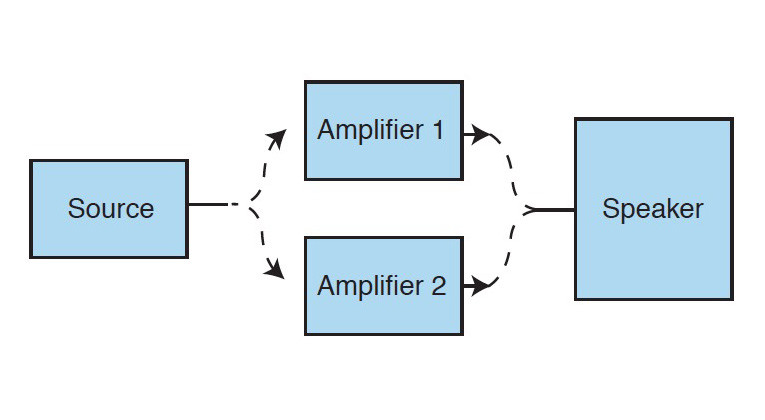
The test setup used for comparing amplifiers can be as simple as the one shown in Figure 1. Since the AES20 recommendations for test procedures are designed to accomplish specific goals, I added comments (in parenthesis) as some of these recommendations are listed. I have not included recommendations that do not apply to amplifier tests.
First, sound levels should be realistic for the type of program material. Second, a previously evaluated “anchor” system should be used for comparison with the unit under test. (This recommendation is not absolutely necessary if the test’s goal is only to compare two or more units, but it is essential for making any sort of absolute judgment of a piece of equipment since even the same listener will experience variations in perception from day to day. Thus, a given listener may rate the same piece of equipment differently on different days unless there is a standard of comparison. Some listeners believe they have time-invariant golden ears. There is no evidence such belief makes them more immune to perceptual variations than other human listeners. Recognizing human limitations is not a sign of weakness, but of scientific integrity.)
Third, in A/B tests, the levels of the “A” and “B” systems must be matched (using pink noise and a sound level meter on slow setting) within 0.5 dB. Fourth, listeners should stand or sit in a variety of locations, moving from time to time during the tests. (This recommendation helps prevent contamination of test results by room-position-dependent acoustical factors.)
Fifth, each program sample should last from 30 s to 60 s. (Shorter clips do not provide sufficient time for a judgment, and longer times risk prolonging the total test to the point of inducing listener fatigue.)
Sixth, trained, experienced listeners should be used. (Studies have shown that untrained listeners tend to show poor consistency, and their responses may tend to cancel statistically, reducing the confidence rating of the test program.
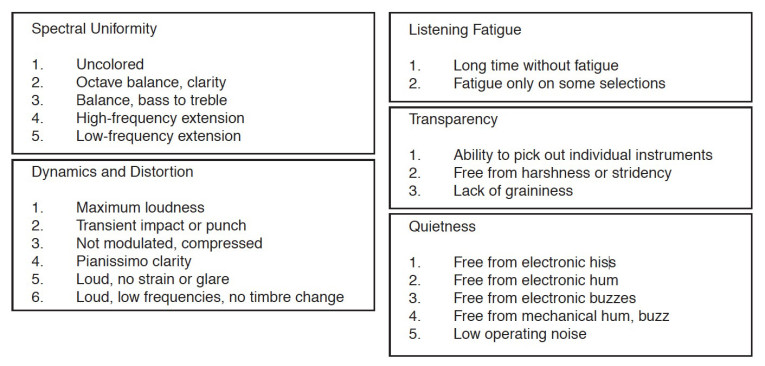
Also, tests using just one listener cannot yield objective results; they can only indicate that listener’s preference.) Seventh, a checklist for characteristics to be described should be used. The use of consistent descriptors that are well-understood by all listeners is vital in order to ensure valid results. (Such descriptors are illustrated in Figure 2.)
Breaks should be taken as needed to avoid listener fatigue. And last, testing should be blind, and, if possible, double-blind. This means that at least the listeners, and preferably those conducting the test, should not know which unit they are evaluating at any particular time. Any form of blind testing adds to the complexity of the process. However, experimental science has established the reality of a placebo effect (i.e., attributing a perceived experience to an incorrect cause).
In tests using expert listeners at an AES meeting some years ago, many listeners heard several solid-state and tube amplifiers, using a wide variety of program material and a double-blind protocol. Listeners were not able to reliably distinguish among the amplifiers, even though many of these professional audio engineers were convinced they heard consistent differences. Refusal to believe in the placebo effect provides no exemption from experiencing it!
Training Program
The training program should involve three primary phases. First, each listener should become familiar with the aural meaning of each descriptor used on the checklist so everyone uses the same vocabulary. Second, each listener should become familiar with the program material, using excellent reproducing equipment. Third, each listener should be qualified for self-consistency using blind listening tests. Any listener’s hearing defects should be noted on the test report.
Blind evaluation of amplifiers requires locating the equipment in another room so listeners never know which amplifier they are hearing at a given time. The most important element in a meaningful subjective test is blind testing. Those who disagree often call upon the proponents of blind testing to prove their cases, or they object to blind testing for reasons that have been more than adequately met in literature from many scientific fields. I submit the absolute requirement of blind testing has been proved, and thus, the onus of proof falls upon those who oppose its necessity.
Blind testing requires at least two participants in the test: one who periodically switches the equipment under test into or out of the audio chain, and the other who listens. The switching protocol should allow for a “switch” operation to either swap or not swap the connections, so when the listener hears artifacts from the switching, (s)he will not know whether a swap has occurred. The person doing the switching must carefully record which piece of equipment was used in each trial, so the equipment’s identity can be correlated with the corresponding listener reports. After one series of trials, the participants can trade positions, so there will be two listeners. Switching can be performed by simple cable swapping. No complex relay arrangements are needed.
Second in importance is correct equipment setup. As an absolute minimum, the test room should not have an unusual acoustical character, in terms of either resonant modes or reverberant characteristics. Speakers should be located to avoid extraneous reflections that can color the sound. Level matching within 0.5 dB is essential. Failure to observe this requirement will invalidate the results, since research has clearly shown listeners relate higher sound level to higher quality, even if they do not consciously recognize the sound level as being higher.
Many articles have been published based on testing that does not adhere to these standards. Thus, much dubious material has been promulgated, contributing more heat than light to the “great debate.”

Art & Science Together
Earlier in this article, I used the phrase “the art and science of sound reproduction and reinforcement.” Too often progress in this field is hindered by our failure to integrate both aspects. But if we scientists will respect the art, and we artists will respect the science, progress will be achieved. In the next article, I will examine results obtained by some excellent researchers. aX
Read Part 2 of this article here.
This article was originally published in audioXpress, October 2012.



